最新发布第3页
排序
【AI语音克隆】GPT-SoVITS V2版,业界最强的AI声音克隆软件、文本转语音工具,新增两种新语种,更强的V2模型
GPT-SoVITS软件由RVC变声器创始人“花儿不哭”大佬开发,GPT-SoVITS的面世,彻底结束了语音克隆被商业垄断的历史,只要你有一张显卡,也能玩曾经高大上的语音克隆了。 项目地址:https://git...
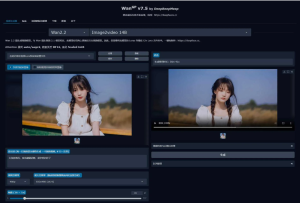
Wan2GP V11版 – 低配显卡玩转AI视频生成,更新Wan2.2图生视频模型 支持50系显卡 一键整合包下载
Wan2GP 是一个由DeepBeepMeep开发的开源视频生成模型项目,旨在为GPU资源有限的用户提供高质量的视频生成体验。它囊括了多种视频生成模型,包括阿里的Wan及其衍生模型、腾讯的Hunyuan Video和LT...
ACE-Step V2版 – 20秒生成4分钟完整歌曲,8G显存可用,小白玩转音乐创作,支持50系显卡 本地一键整合包下载
ACE-Step 是由ACE Studio与StepFun联合开发的音乐生成模型,被誉为“音乐界的Stable Diffusion”。该模型以其惊人的生成速度和多样化功能引发行业热议,支持19种语言,可在短短20秒内生成一首长...
GPT-SoVITS_V4一键整合包
GPT_SoVITS的介绍 GPT_SoVITS 是一种结合了 GPT(生成预训练模型)和 SoVITS(Singing Voice Conversion via Variational Information Bottleneck Technology)的模型,主要用于声音(主要是歌...
DiffRhythm(谛韵) V3版 – AI音乐创作新纪元,新增完整版(4分45秒模型),10 秒生成 AI 歌曲,本地一键整合包下载
DiffRhythm(谛韵) 是第一个开源的基于扩散的音乐生成模型,能自动生成包含人声和伴奏的完整歌曲。该名称结合了 “Diff” (引用其扩散架构) 和 “Rhythm” (突出其对音乐和歌曲创作的关注...

解决主体一致性了!FLUX.1 Kontext 深度测评+案例实操教程
5 月 29 日,黑森林实验室发布了 FLUX.1 Kontext,目标是通过一个统一的框架处理多种图像任务,解决现有模型在多轮编辑中的一些关键痛点。 先说结论:可以解决一些,但解决得还不够,但如果继...

FLUX.1模型(Fill、Canny、Depth 和 Redux):支持局部重绘/扩图/风格变体
Black Forest Labs 推出四款功能性模型,显著扩展了 Flux 生态的图像创作能力。此次更新包含 Fill、Canny、Depth 和 Redux 四大模型,支持外绘扩展(outpainting)、局部重绘(inpainting)、风...

Z-Image – 秒级生成+照片级逼真文生图神器 8G显存可用 支持50系显卡 WebUI+ComfyUI工作流 一键整合包下载
Z-Image(造相)是阿里巴巴通义实验室最新开源的一个强大且高效的图像生成模型,凭借轻量参数实现重量级模型的视觉质量,支持中英双语渲染并在消费级显卡上实现秒级出图。 今天分享的 Z-Imag...
Wan2.2AllInOne V6版 – 极速AI视频生成神器,新增Lora 更新Mega V12模型,支持NSFW WebUI+ComfyUI工作流 一键整合包下载
Wan2.2 AllInOne 是阿里万相团队开源的 WAN2.2 视频模型的“大一统”整合版本,通过融合多款子模型实现极速视频生成,兼具影视级画质与简洁操作,是当前 AI 视频生成领域的标志性工具。 Wan2.2A...

超详细提示词教程|玩转Wan2.2
想让 Wan2.2 生成你心中的画面? 关键在提示词怎么写。 本文将带你掌握文生视频 Prompt 写作技巧,建议收藏+关注! 提示词公式 提示词用来描述视频中所包含的内容和运动过程,它是控制视...
