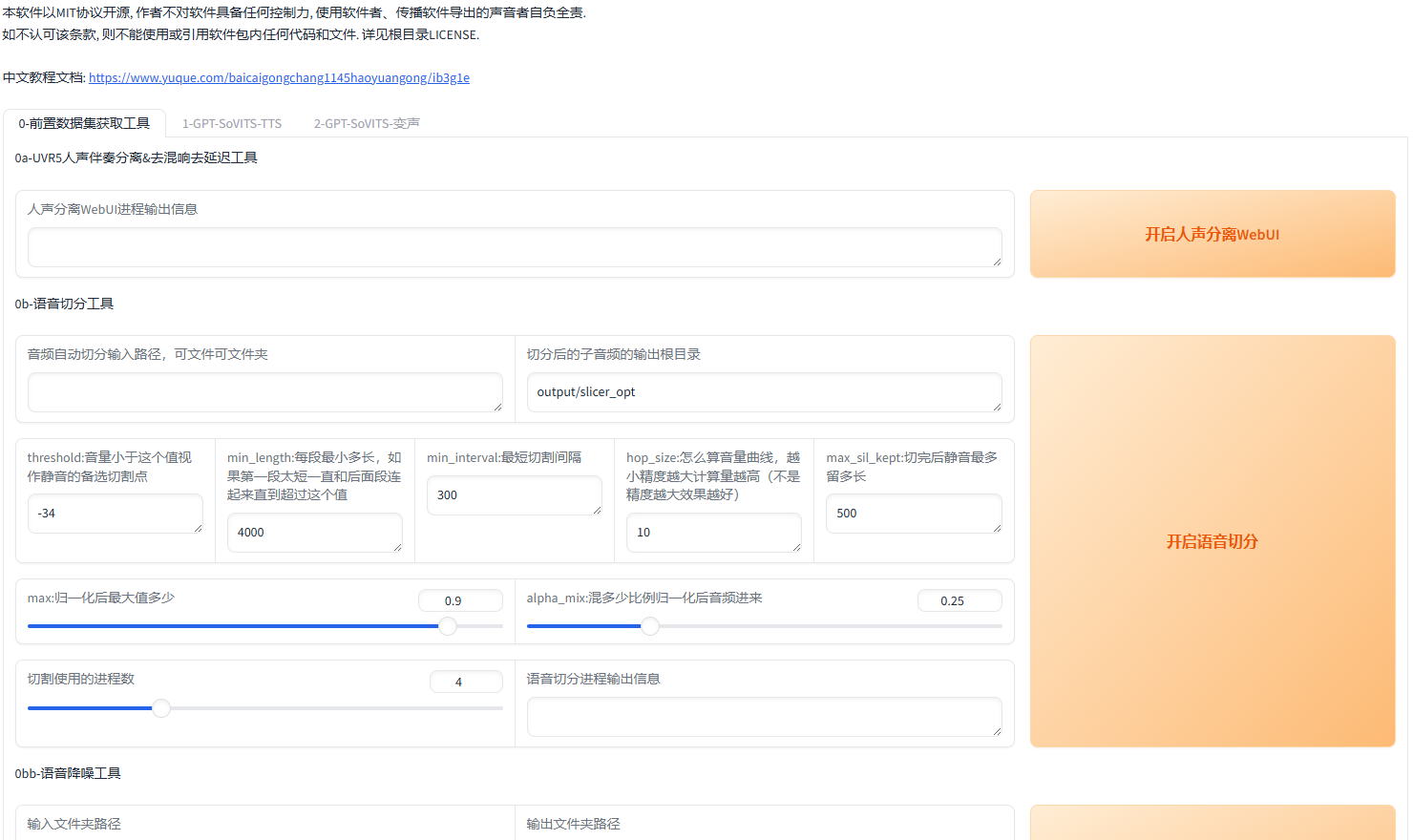

GPT_SoVITS的介绍
GPT_SoVITS 是一种结合了 GPT(生成预训练模型)和 SoVITS(Singing Voice Conversion via Variational Information Bottleneck Technology)的模型,主要用于声音(主要是歌声)转换任务。它将语音转换技术与生成模型的强大功能相结合,实现了更为自然、逼真且高效的声音转换。
GPT_SoVITS 的优点
- 高质量转换:借助 GPT 的强大生成能力,转换后的歌声更加自然和流畅。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语、韩语、粤语和中文。
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
- 端到端训练:模型可以直接从输入到输出进行训练,无需复杂的中间处理步骤。
GPT-SoVITS_V4一键整合包
支持一键启动和离线运行,兼顾隐私安全。配备图形化界面,操作简单,可快速生成个性化语音,适合技术爱好者与研究者使用。
主要亮点
无需部署,一键启动即用。为 Windows 10/11(64位)用户准备了一键启动包,下载解压后双击即可打开本地 WebUI,轻松上手,无需繁琐设置。
推荐配置:8GB 以上显存的 NVIDIA 显卡,安装 CUDA 12.1 或更高版本,确保流畅运行。
功能一应俱全:
- 并行推理:显著提升处理速度
- 训练集格式化:整理数据更高效
- 微调训练:打造个性语音模型
- 中文语音识别(ASR):自动转写语音内容
- 文本标注:加速语料整理
- 语音伴奏分离:提取清晰人声
无论是初学者还是进阶用户,GPT-SoVITS V4 都是打造专属语音的理想工具。
使用指南
安装GPT_SoVITS
第一步:下载GPT_SoVITS
注册用户后签到即可获取积分用于下载,也可以直接充值下载。本站的资源完全可以通过签到获取积分进行下载而无需充值。
第二步:解压整合包
下载完成后,将压缩包解压到你的电脑的英文目录下。切记不要使用中文路径,否则可能会导致程序运行出错。
第三步:启动程序
- 双击 go-webui.bat 文件,启动 GPT-SoVITS_V4 的后台服务。
- 程序启动后,可能会弹出命令行窗口,显示程序的运行状态和日志信息。请不要关闭此窗口,除非你想停止程序运行。

第四步:访问WebUI界面
- 程序成功启动后,会自动打开你的默认浏览器,并访问 WebUI 界面。
- 如果浏览器没有自动打开,你可以在浏览器地址栏手动输入
http://127.0.0.1:9874(或者启动程序显示的地址) 来访问 WebUI 界面。
训练模型
1. 准备训练的声音素材
2. 音频提纯:如果原音频干净无杂音,可以直接使用,跳过对音频提纯的处理步骤。
如果你的音频里有伴奏或者混响,可以使用UVR5人声伴奏分离&去混响去延迟工具,首先点击开启人声分离WebUI,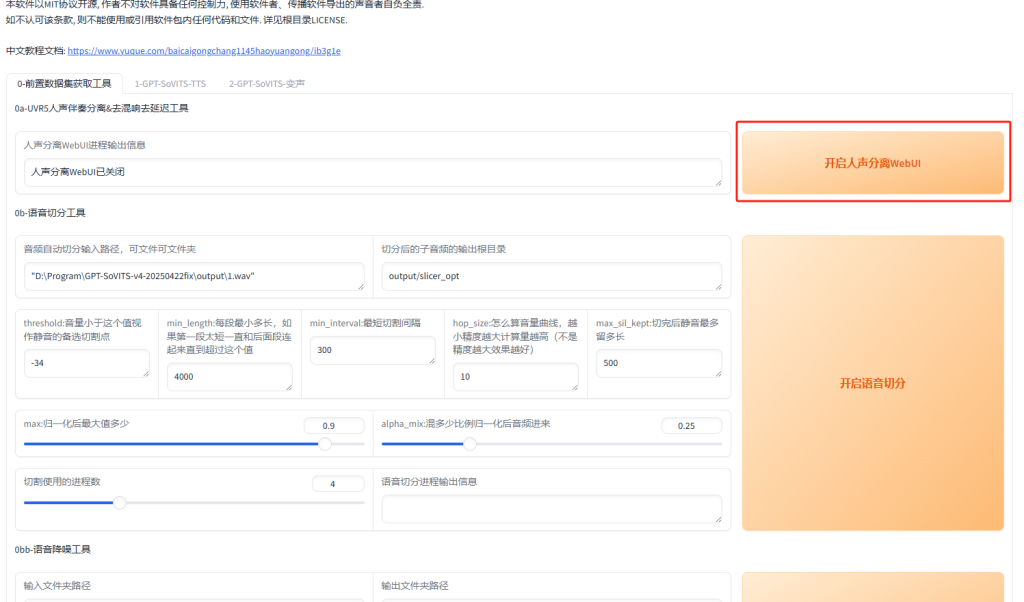
会跳到UVR5-WebUI的处理界面,如果使用过RVC-WebUI的小伙伴应该很熟悉这个界面了。
然后输入待处理音频的路径,这里有两种方式,一种是输入音频文件夹路径,一个是点击批量上传。
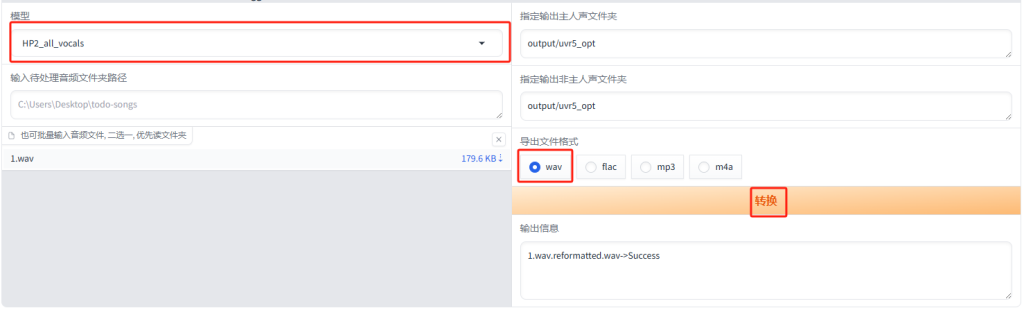
使用音频文件夹路径,需要先在文件管理里创建待处理音频文件夹,上传音频文件。然后复制文件夹地址。
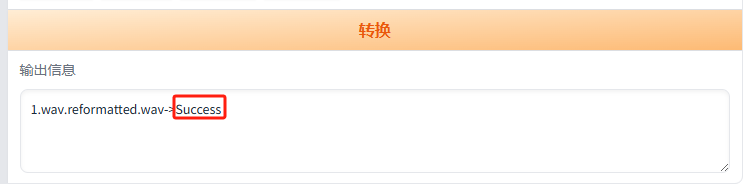
可以先使用HP2模型处理一遍(提取人声),然后将输出的音频再用onnx_dereverb去混响、去延迟,再使用DeEcho-Aggressive去除音频中的回声,注意:输出格式选wav。看到输出信息->Success说明处理好了。
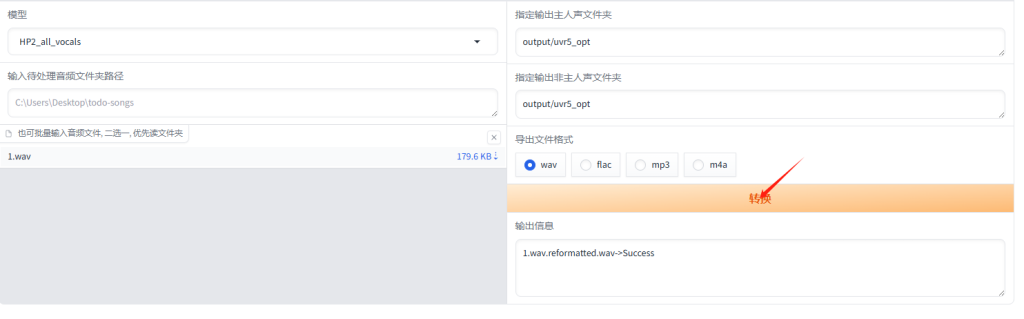
可以看到output/uvr5_opt下面输出,处理完的音频(vocal)的是人声,(instrument)是伴奏,现在我们只需要保留人声的音频,去进一步操作。(如果你觉得这一步的音频效果已经达到要求,可以直接使用,不用进一步提纯,onnx_dereverb这一步还是挺耗时的。)
我们输出的文件默认在output/uvr5_opt下面,可以把一些用不到的删掉,避免取错文件。
最后只需要音频(vocal)的人声,其它都删掉。
注:处理完声音,我们就可以关闭UVR5-WebUI以节省显存。
3. 切割音频
首先输入原音频的文件夹路径,不能是中文名,如果刚刚处理的音频文件放在uvr5_opt这个文件夹,那直接使用即可。(当然也可以放在其它文件夹里)切割输出的结果放在output/slicer_opt文件下。
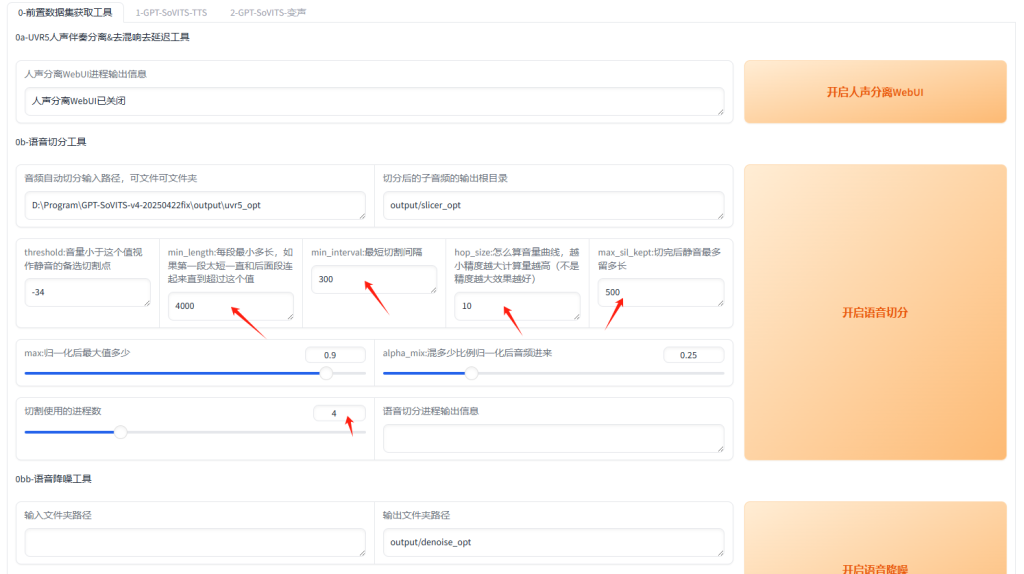
语音切割进程输出信息显示:语音切分已完成,即可。
调整参数:
- min_length:根据显存大小调整,显存越小调越小
- min_interval:根据音频的平均间隔调整,如果音频太密集可以适当调低
- max_sil_kept:会影响句子的连贯性,不同音频不同调整,不会调的话建议保持默认
4. 语音降噪
这一功能对音质的破坏很大,不太建议使用该步骤,如果你想用也可以

5. 语音识别
就是给每个音频配上文字,使AI识别学习。
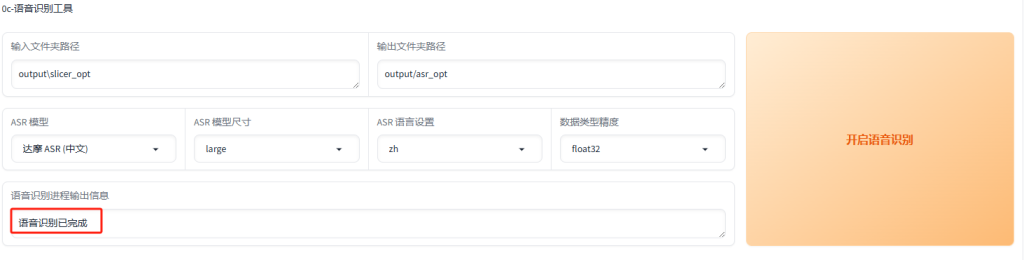
语音识别进程输出信息输出:语音识别已完成,即可。
6. 语音文本校对
这一步骤也是一个非必须项,因为比较耗时,如果不追求极致完美,可以跳过。
如果需要就先开启打标WebUI,输入标注文件的文件路径,注意是文件路径!不是文件夹路径!

开启音频标注WebUI,会打开一个链接:http://localhost:9871/,打开时打标WebUI界面。
这一步可以自己去看看教程。
7. 开始训练
点击”1-GPT-SoVITS-TTS”选项,进入训练界面。
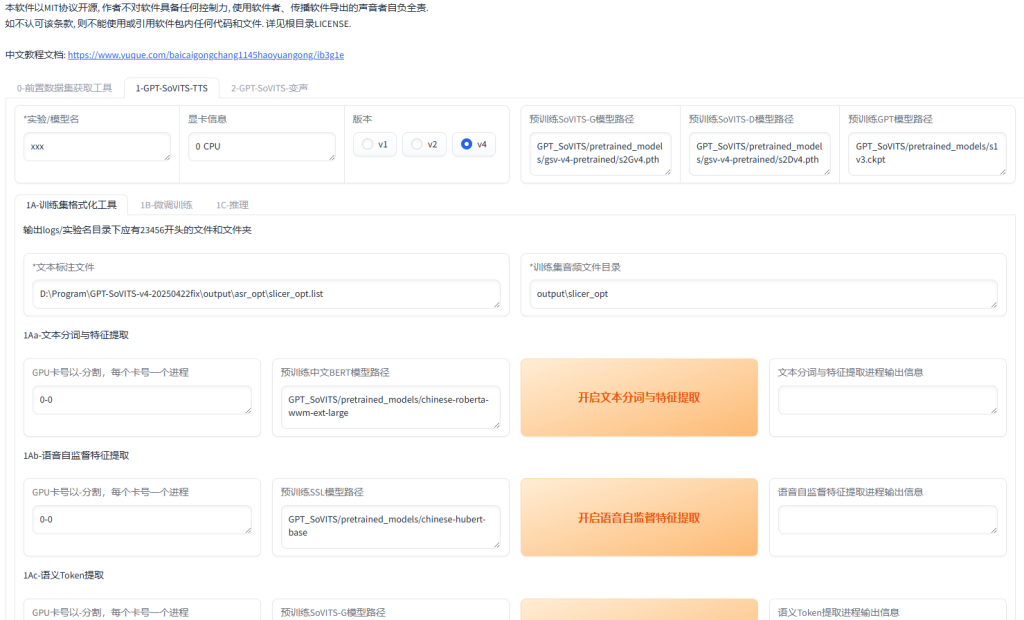
训练步骤:
- 首先,输入模型的名字,可以是中文。
- 选择训练的版本
- 最后点击”一键三连”
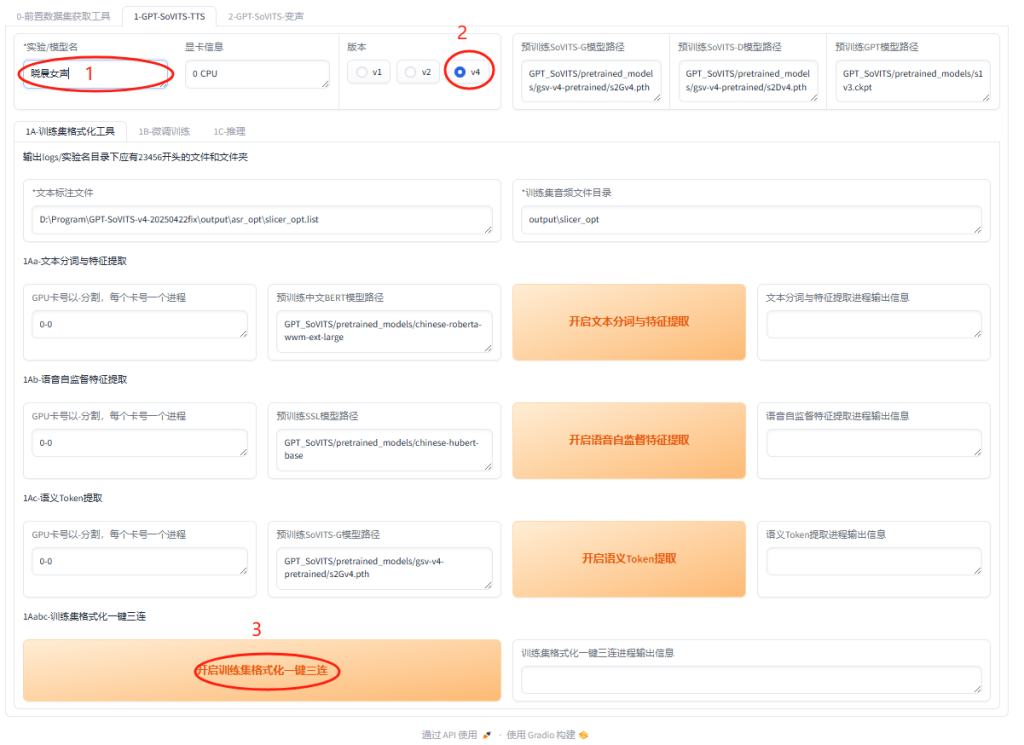
一键三连进程输出信息显示:一键三连进程结束,即可!
8. 微调训练
点击”1B-微调训练”,进入微调训练界面。
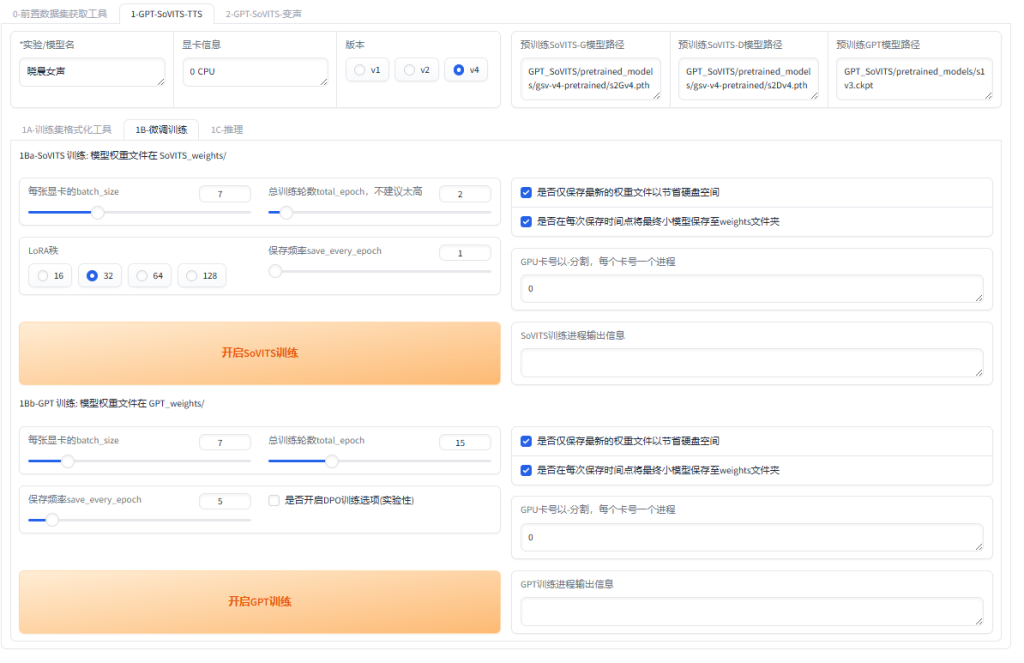
调整参数:
- batch_size:在设置 `batch_size` 时,建议将其设置为显存容量的一半以下。过高的 `batch_size` 会导致显存溢出。需要注意的是,`batch_size` 并不是越高越好、越高越快的。在实际操作中,`batch_size` 还应根据数据集的大小进行调整,并不严格按照显存容量的一半来设置。例如,6GB 显存建议将 `batch_size` 设置为 1。如果出现显存溢出的情况,可以适当降低 `batch_size`。
- total_epoch:SoVITS模型轮数可以设置的高一点,但是GPT模型轮数千万不能高于20(一般情况下)建议设置10。
- 是否开启dpo训练:不建议开启
其它参数建议默认。
然后先点开启SoVITS训练,训练完后再点开启GPT训练,不可以一起训练。
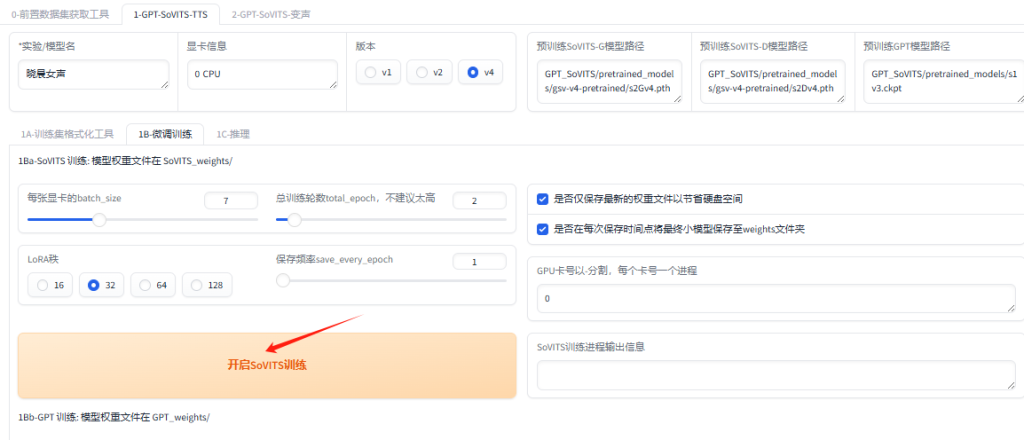
SoVITS训练完成,接下来点击”开启GPT训练”
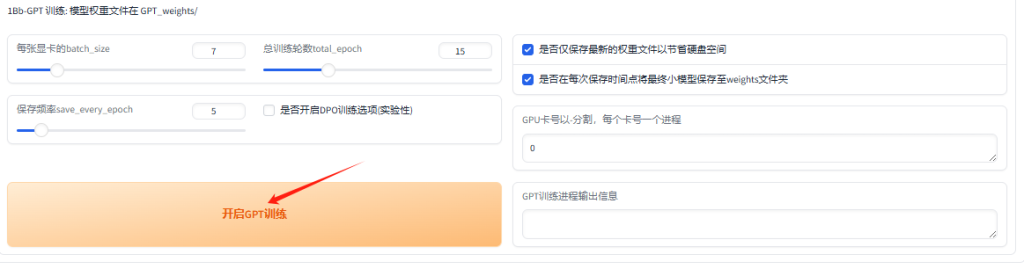
GPT训练完成,即可。
语音合成
1. 开启TTS推理
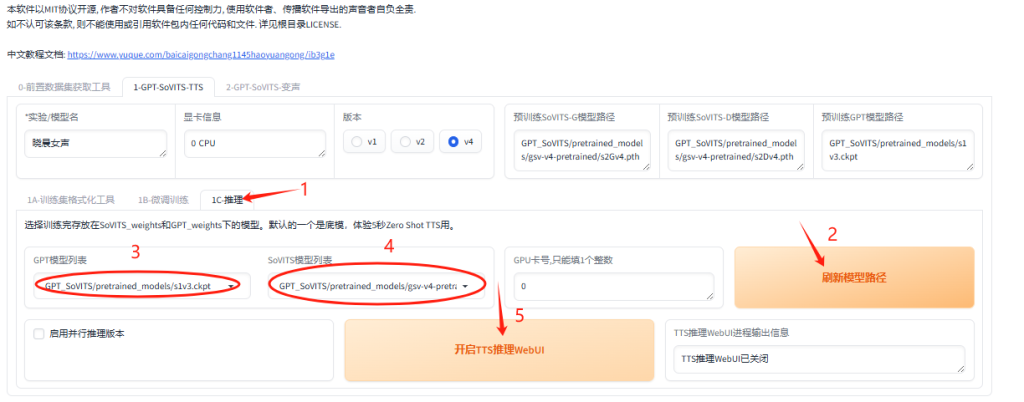
- 点击”1C-推理选项”,进入推理界面。
- 点击刷新模型路径显示刚刚训练的模型
- 选择模型
- 开启WebUI界面,这时会自动打开推理界面
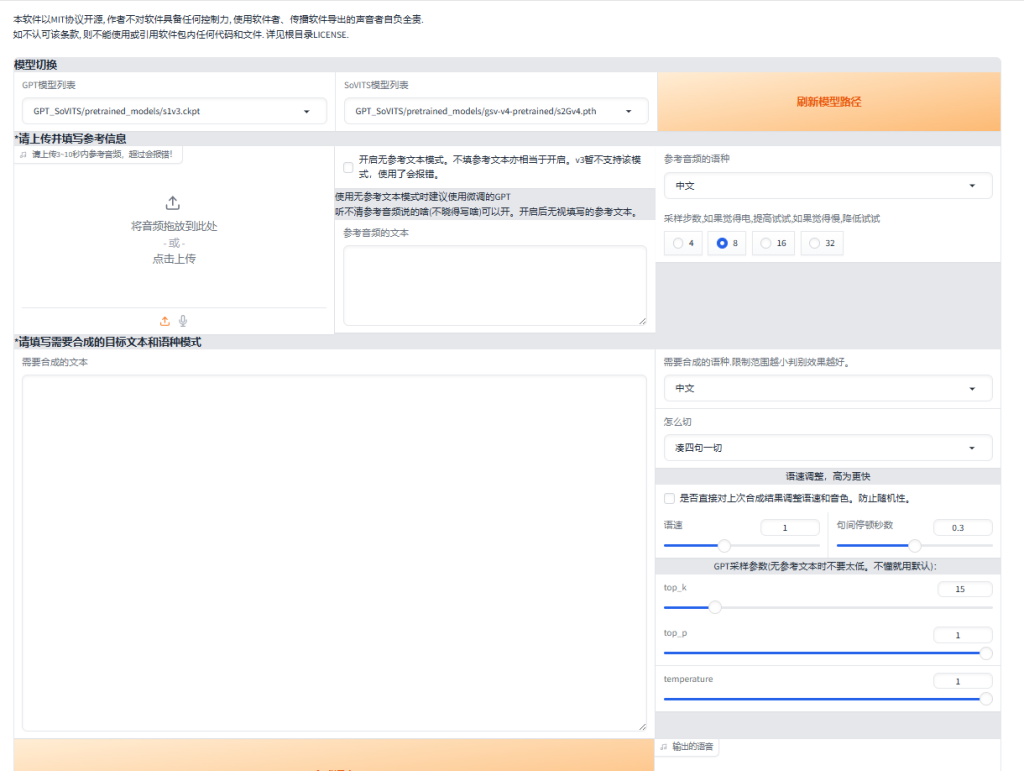
推理步骤:
- 选择GPT模型
- SoVITS模型
- 上传参考音频,不要太长
- 填写参考音频的文本,参考音频里说了什么或者唱了什么都要写,尽量不要开启无文本模式
- 填写需要合成的目标音频的文本
其它参数默认就行了。
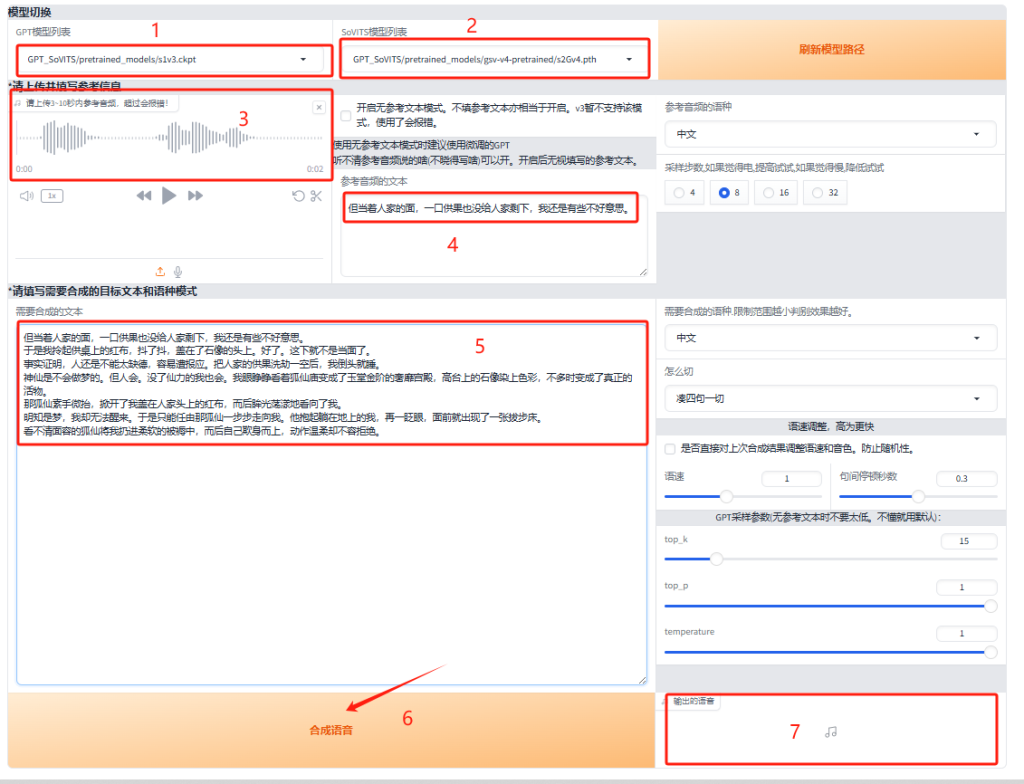
输出音频,可以下载。
以上就是GPT_SoVITS训练的全部内容。
![[绘画教程] Comfyui,最强图片编辑模型轻松脱衣,支持50系列显卡-AIGC VIP部落](http://aigc.vvipblog.net/wp-content/uploads/2025/07/1752548383-61cd49faf155bb2-300x188.png)

![【Windows】 已破解AI去衣换装扩图软件:MagicQuillv2.0+模型+教程 [1+31g][百度盘]-AIGC VIP部落](http://aigc.vvipblog.net/wp-content/uploads/2025/05/1746632625-d65b39fec71f2ea-300x204.png)



暂无评论内容