


一.底层逻辑
在Comfyui里面,我们可以看到有着密密麻麻的各种各样的节点,但这些都是插件类的节点,很多都是极少用到的,但这里面有5类基础节点,几乎在每个工作流里面都是一定会用上的,下面我们来一一了解一下。
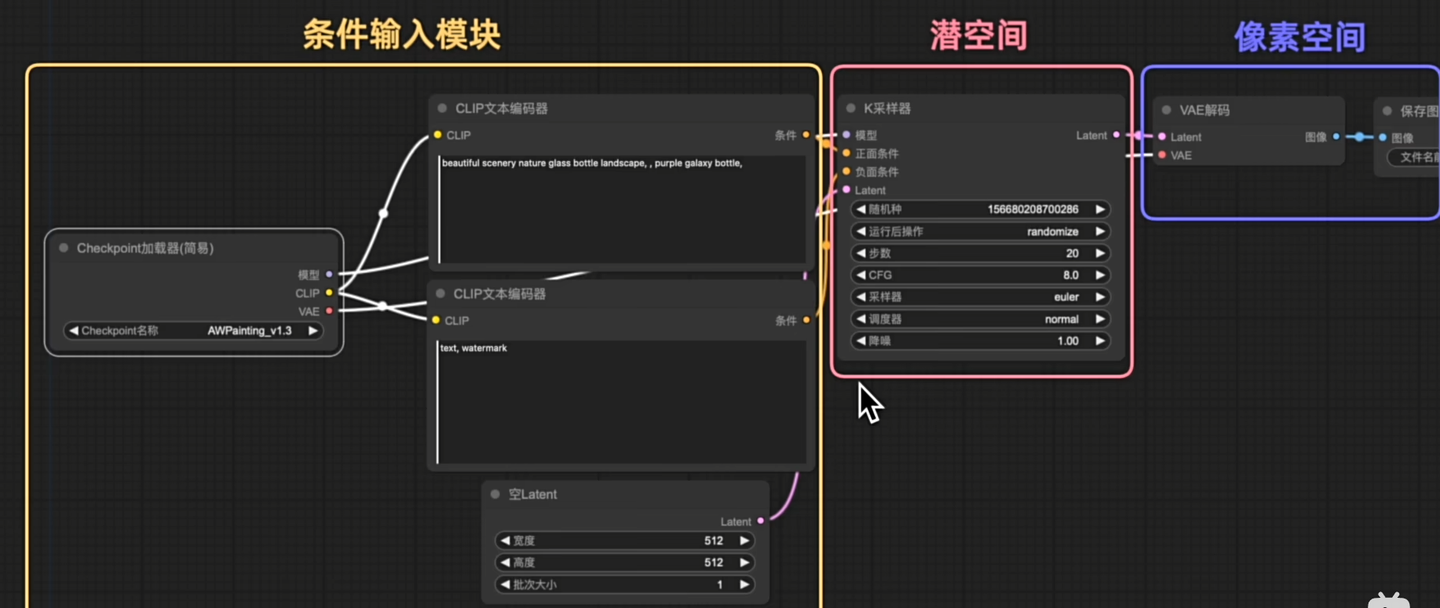
1.文生图
大部分的工作流都是从基础的文生图开始扩展
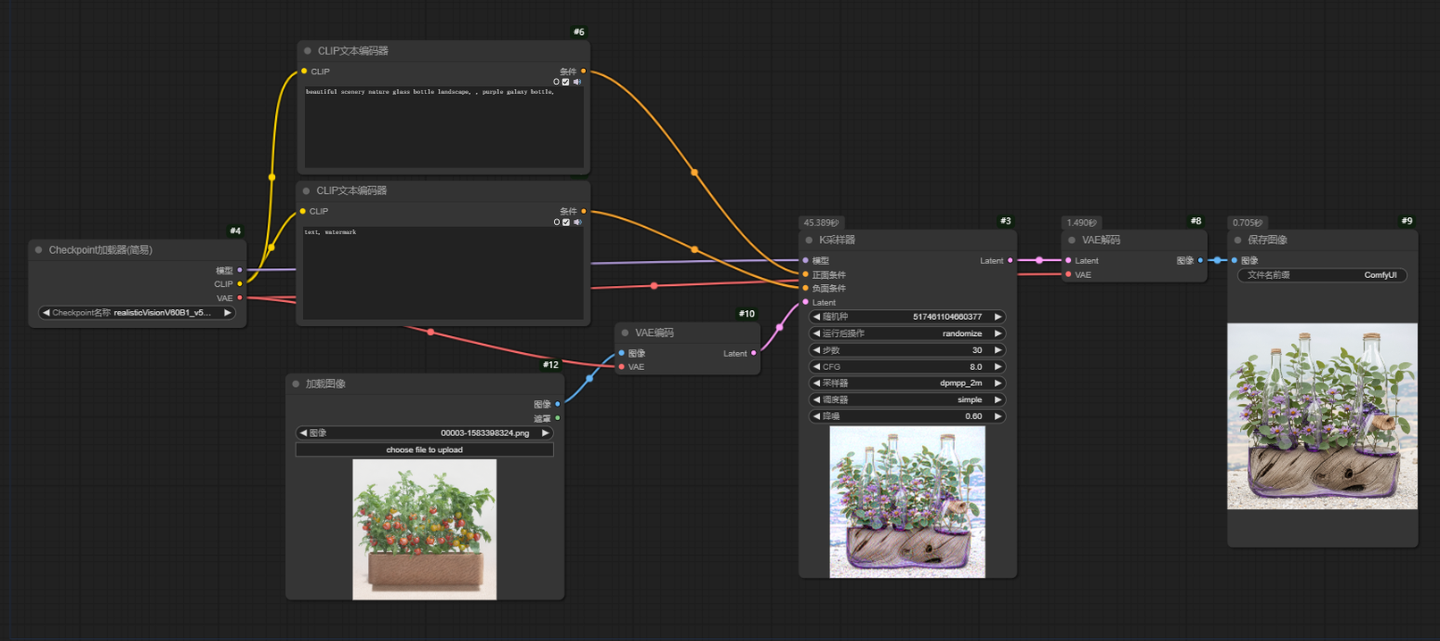
2.图生图
图生图与文生图基本一样,文生图是给潜空间图一个空的latent,用来定义生成图片的大小。而图生图则是需要给到潜空间一张图片做参考,而图片无法直接给到潜空间,这时就需要在中间加个VAE编码了。
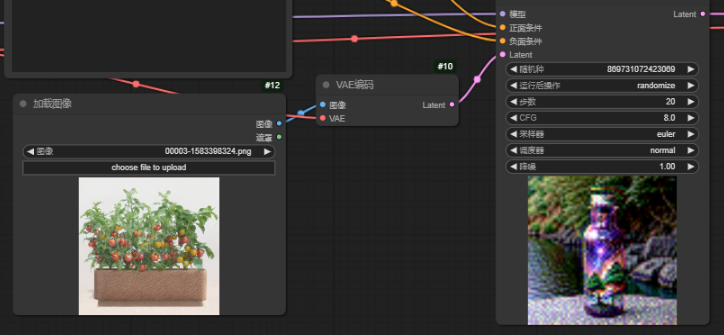
Latent -> 经过 KSampler 采样器进行去噪后的潜空间图像
降噪 -> 需要注意的是图生图时,在这里降噪可以理解为重绘幅度
3.局部重绘
谈到局部重绘就会牵扯到遮罩,也就是通过制作遮罩的方式对图像的特点部分进行处理。制作遮罩的工具有maskeditor(遮罩编辑器),或者segment anything(语义分割)等等!
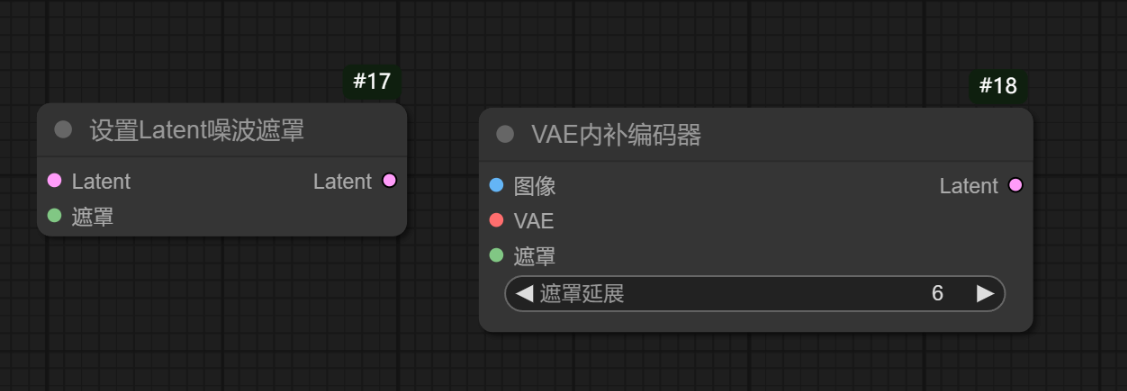
3.1系统自带局部重绘comfyUI自带的两个重绘节点Laten噪波遮罩Set Latent Noise Mask,VAE内补编码器VAE Encode (for inpainting)有一个很大的缺点就是他们都会对全图进行重绘。无论蒙版多小,重绘时间和资源占用是根据整个图片的大小来重绘的。导致对高分辨率图片细节重绘时又慢又容易爆显存。
在输入图片上右键选择在遮罩编辑器打开Open in MakeEditor,将要重绘的面部给完全涂抹,之后进行保存。
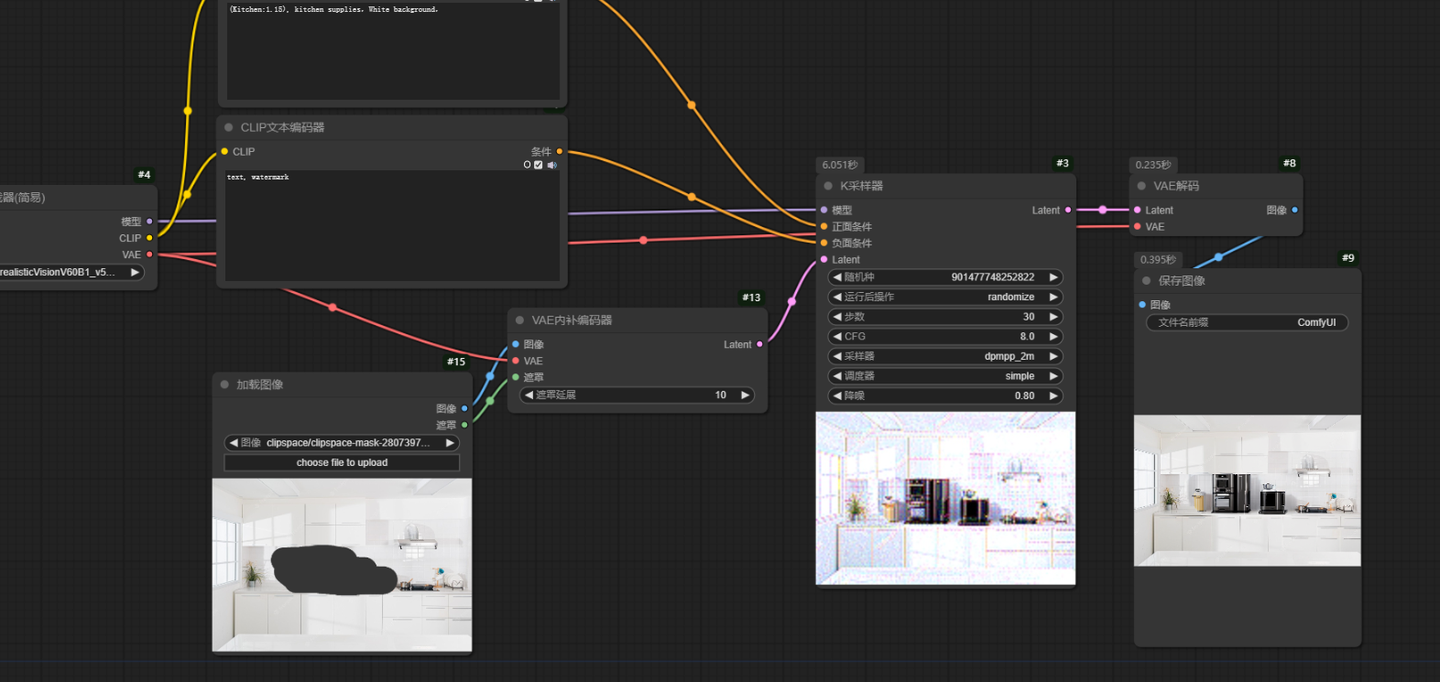
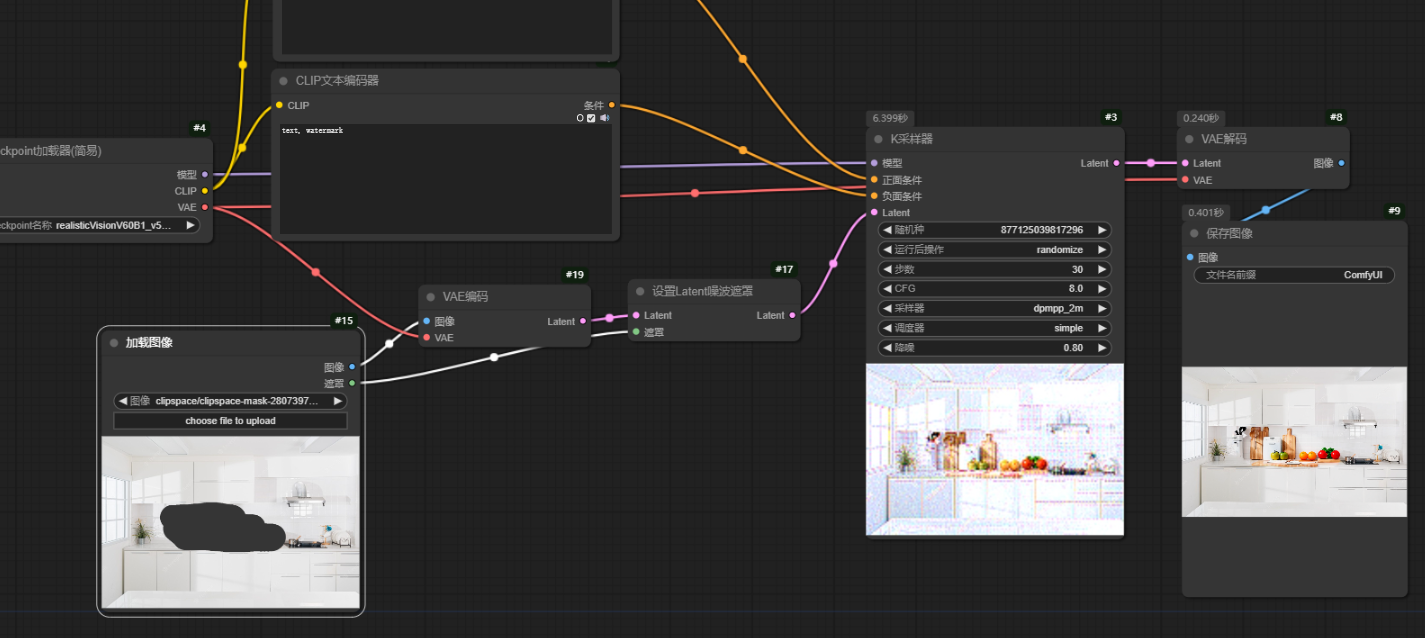
comfyUI自带的两个图生图节点都不能很好的做到。
3.2 segment anything + BrushNet【语义分割+局部重绘】
3.3 Impact Pack那么换个思路,我们可以将高分辨率图片的蒙版周围区域剪切一部分,比如剪切一个512*512的区域来重绘,这样既快,而且图片和周围的区域融合的也比较自然。
我们使用的是Impact Pack 插件(这插件功能很多也很强大,后面会出个专栏介绍他的所有功能,有兴趣可以持续关注)
二.采样类
1.K采样器
该节点专门用于逐步减少潜在空间图像中的噪声,改善图像质量和清晰度。
把它拿出来第一个说就说明这个节点的重要性,所有的工作流都是围绕着它来进行扩散的。
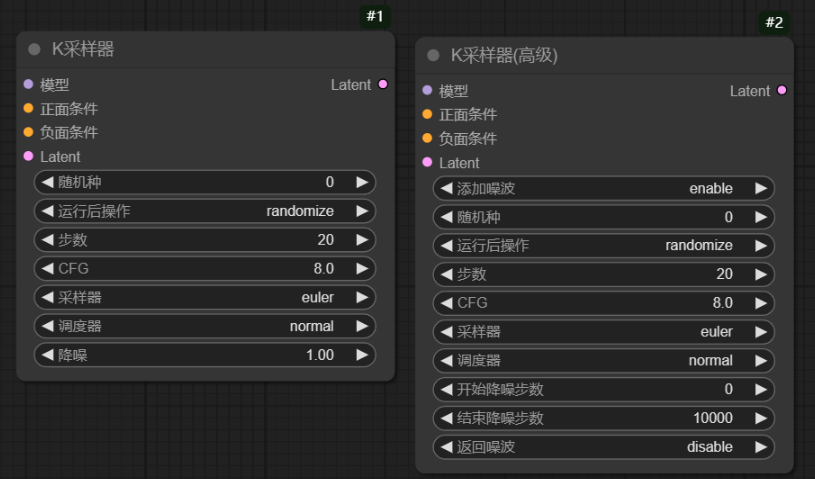
输入:
模型model -> 接收来自大模型的数据流 positive -> 接收经过 clip 编码后的正向提示词的条件信息(CONDITIONING) negative -> 接收经过 clip 编码后的反向提示词的条件信息(CONDITIONING) latent_image -> 接收潜空间图像信息
输出:
LATENT -> 经过 KSampler 采样器进行去噪后的潜空间图像
参数:
随机种seed -> 在去除图像噪声过程中使用的随机数种子。种子数有限,影响噪声生成的结果。
运行后操作 -> 指定种子生成后的控制方式。 固定fixed 代表固定种子,保持不变;增加 increment 代表每次增加 1; 减少decrement 代表每次减少 1 ;随机randomize 代表随机选择种子 。
步数steps -> 对潜在空间图像进行去噪的步数。步数越多,去除噪声的效果可能越显著。
CFG -> 提示词引导系数,表示提示词对最终结果的影响程度。过高的值可能会产生不良影响。
采样器 -> 选择的采样器名称,不同的采样器可以影响生成图像的效果,大家可以根据需求进行选择和实验。
调度器scheduler -> 选择的调度器名称,影响生成过程中的采样和控制策略,推荐配置可提供更好的结果。
降噪denoise -> 去噪或重绘的幅度,数值越大,图像变化和影响越显著。在高清修复等任务中,通常使用较小的值以保持图像细节和质量。
采样器+调度器参数:
我们之前最熟悉的采样器,有euler、dpmpp_2m,包括后来的ddpm、ddim、uni_pc和ipndm等。
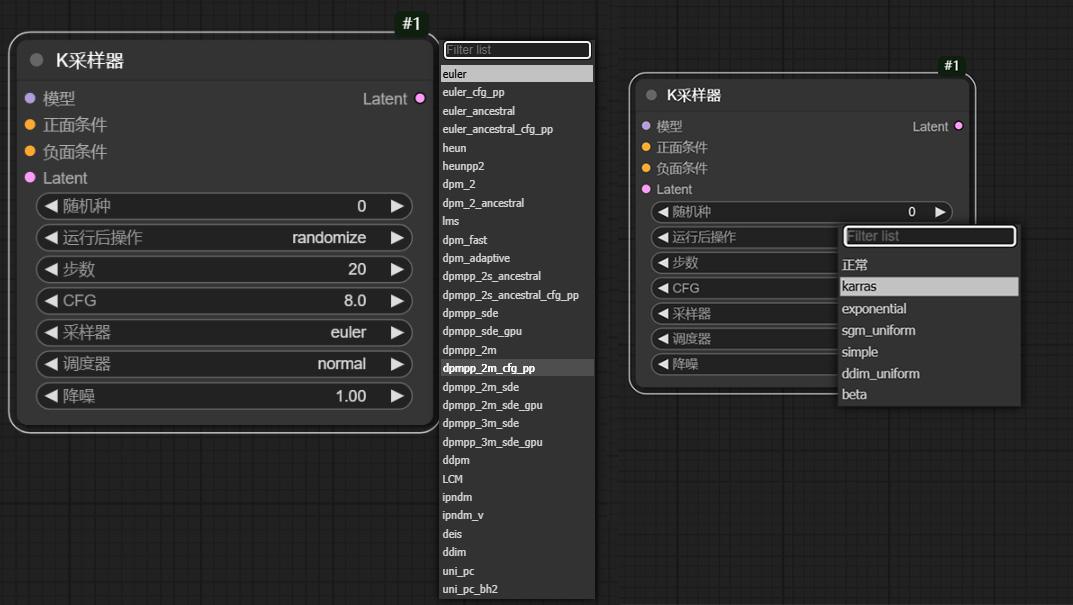
采样器:
采样器有点多,看起来有点蒙逼。其实可以把它分成三类:
01欧拉: euler和heun 02dpm :所有以dpm开头 03 其它类
对比测试
建立一个XY图表,横坐标是步数,从第5步开始,间隔四步,总共8个数值;纵坐标是上面介绍的各种采样器。

从上图中不难发现如下规律:
·名字以a或sde结尾的,确实不会收敛,每一步选代图像都会发生变化 ·euler,heun和ddim采样器在第9步就已经出图,对于简单图来说,确实是又好又快。 ·dpmpp_2m和uni_pc采样器在第14步出图,其中dpmpp_2m在第18步开始收敛,效果很好 ·不要被dpm adaptive采样器骗了,虽然第5步就已经收敛,但是该采样器速度特别慢。后续我又单独进行了测试,实际第2步就已经收敛,但是速度很慢。 ·Ims采样器表现最差。
如何选择采样器?
没有最好的采样器,只有最适合的采样器。
如果想要稳定可重现的图像,请避免选择任何祖先采样器(名字以a或sde结尾的) 如果想要简单的图,建议选择euler,heun(可以减少步骤以节省时间) 如果想快速生成质量不错的图片,建议选择dpmpp_2m(20-30步)、uni_pc(15-25步) 如果想要每次生成不一样的图像,可以选择不收敛的祖先采样器(名字里面带a或sde)
调度器则就相对来得简单些:
最常见的normal似乎已不太适用于FLUX生态 以往最常用的karras也在sgm_uniform、simple、ddim_uniform和beta出现后被慢慢淡化。 其中,ddim_uniform这个调度器,会随着采样的步数,构图画面会发生一定的变化,因为它有点像高级的调度器dpm一样,是不收敛的,则出图的多样性随机性会随着步数增加更强,变化更多。 对于调度器exponential,则较多用于扩图放大等情况。
国外有位大佬对Flux各种采样器和调度器进行组合测试出最适合的采样模式。表格中的绿色标记表示该组合可用,红色标记表示不可用。
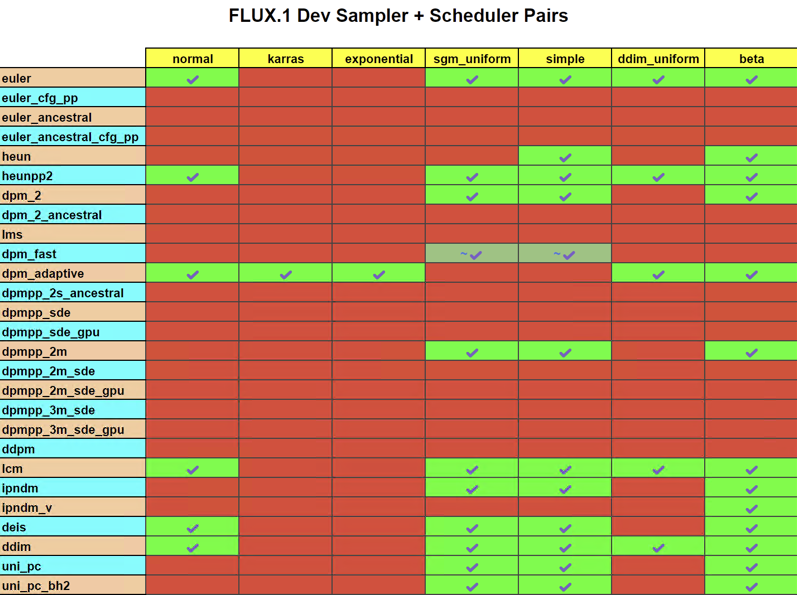
推荐的采样器和调度器组合:
euler + normal:适用于快速生成图像,但细节可能不够精细。(生成时间20s)
heunpp2 + ddim_uniform:适用于生成细节丰富的图像,但速度较慢。(生成时间54s)
uni_pc +beta:适用于平衡速度和质量,是大多数情况下的推荐选择。(生成时间20s)
DPM2+ SIMPLE是我最近比较喜欢的组合,能够提供非常好的图片精细度。(生成时间37s)
DEIS+DDIM_UNIFORM是新出现的组合,非常好的把握光影明暗。(生成时间20s)
三.加载器
ComfyUI基础节点中的加载器类别,加载器是工作流中各个模块的生产力源头,可以提供不同模型的加载。下面详细介绍了trap point加载器、VA1加载器、LUA加载器、control加载器、clip视觉加载器、n clip trip point加载器、格莱根加载器和超网络加载器的作用和使用方法。通过加载器可以方便地选择不同的模型进行加载和应用,提高工作流的效率和灵活性。
所谓的加载器主要的作用就是给工作流提供各种不同模型的加载,大部分的工作流都是以大模型的加载作为起始输入源来进行展开的。
一个工作流里可能存在多个加载器,例如对图片进行放大,需要用到放大模型加载器。连接controlnet时需要controlnet加载器。
1.Checkpoint加载器
【加载大模型】
节点功能:该节点用来加载checkpoint大模型,常用的大模型有sd1.0,sd1.5,sd2.0,sdxl等等。
输入:
扩散模型的路径 **假如配置好了路径文件,模型可自行选择**
输出:
MODEL -> 该模型用于对潜空间图片进行去噪
CLIP -> 返回与加载的检查点关联的CLIP模型。
VAE -> 返回与加载的检查点关联的VAE模型。用于对潜在空间的图像进行编码和解码。
注意:StableDIffusion大模型(checkpoint)内置有CLIP和VAE模型。
2.VAE加载器
大模型都自带有VAE,如果你不想使用大模型的VAE时,就可以新建一个VAE加载器
3.lora加载器
【预训练模型微调调整】
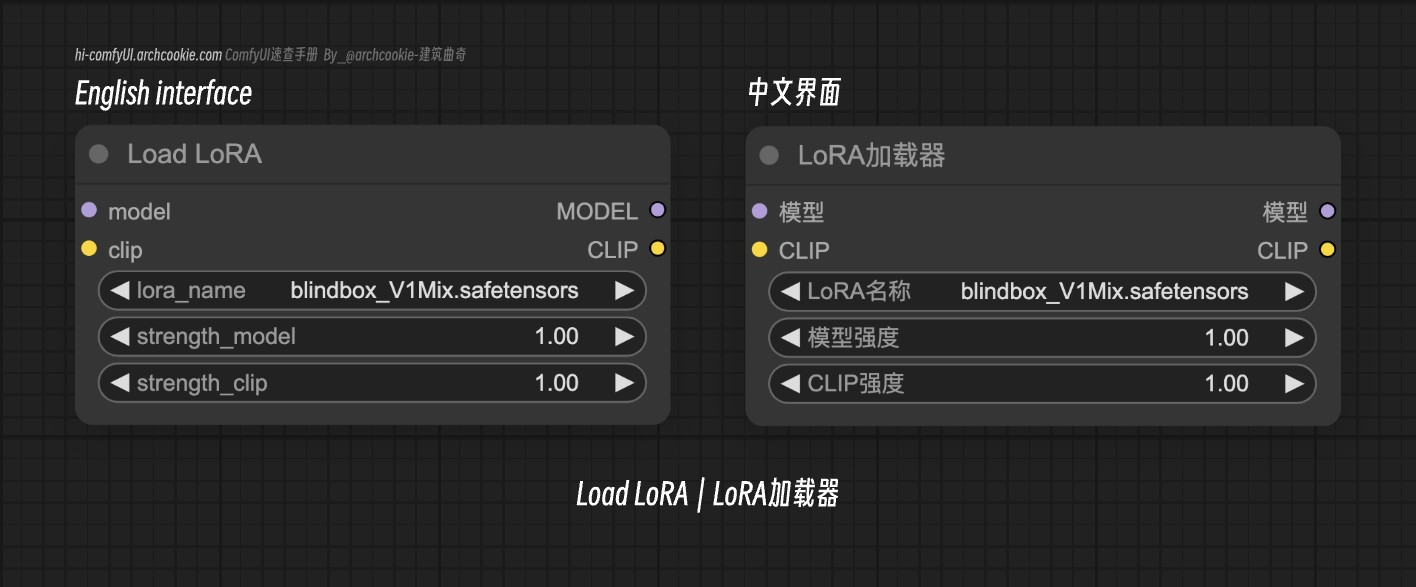
模型强度 -> 确定应用于模型的LoRA调整的强度。更高的强度意味着更显著的调整,可能导致模型行为的显著变化,潜在地提高特定任务的性能。
CLIP强度 -> 与模型强度类似,更高的强度导致更明显的变化,影响CLIP模型处理数据的方式。
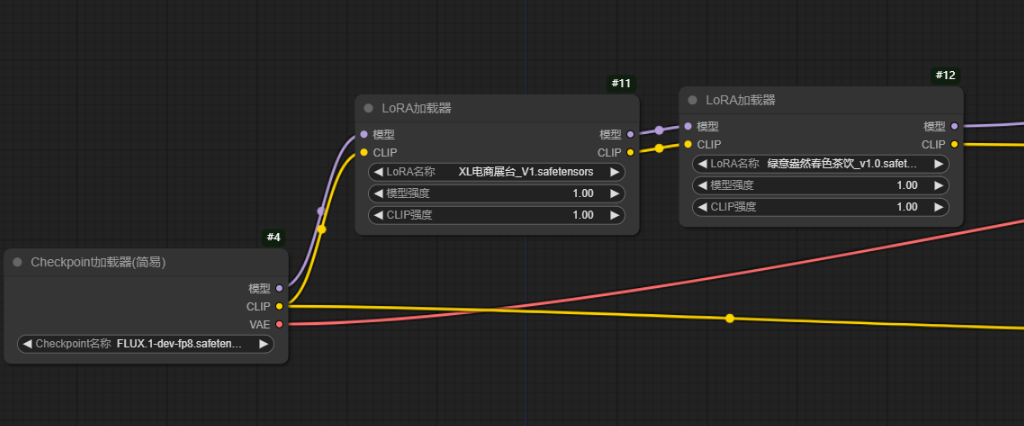
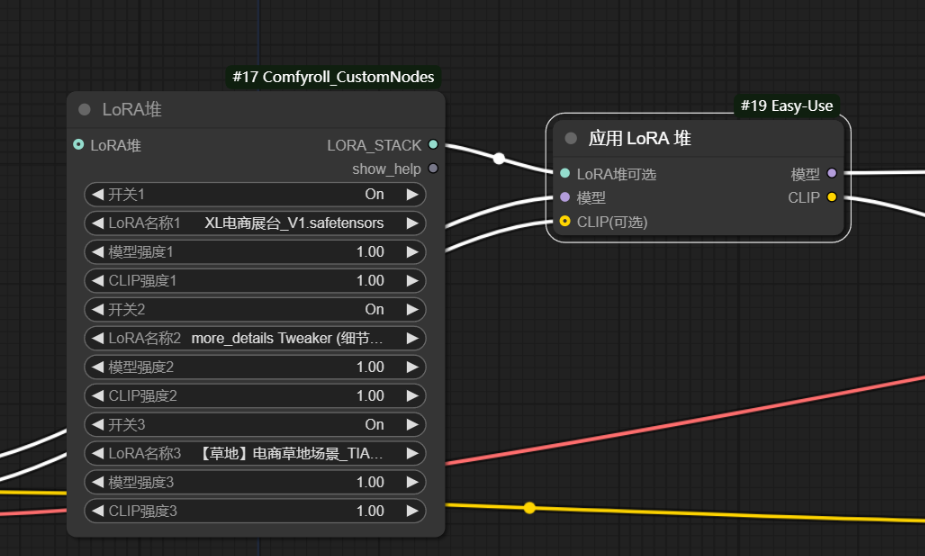
当需要多个lora时,串联下去比较麻烦,这时我们就可以使用lora堆节点
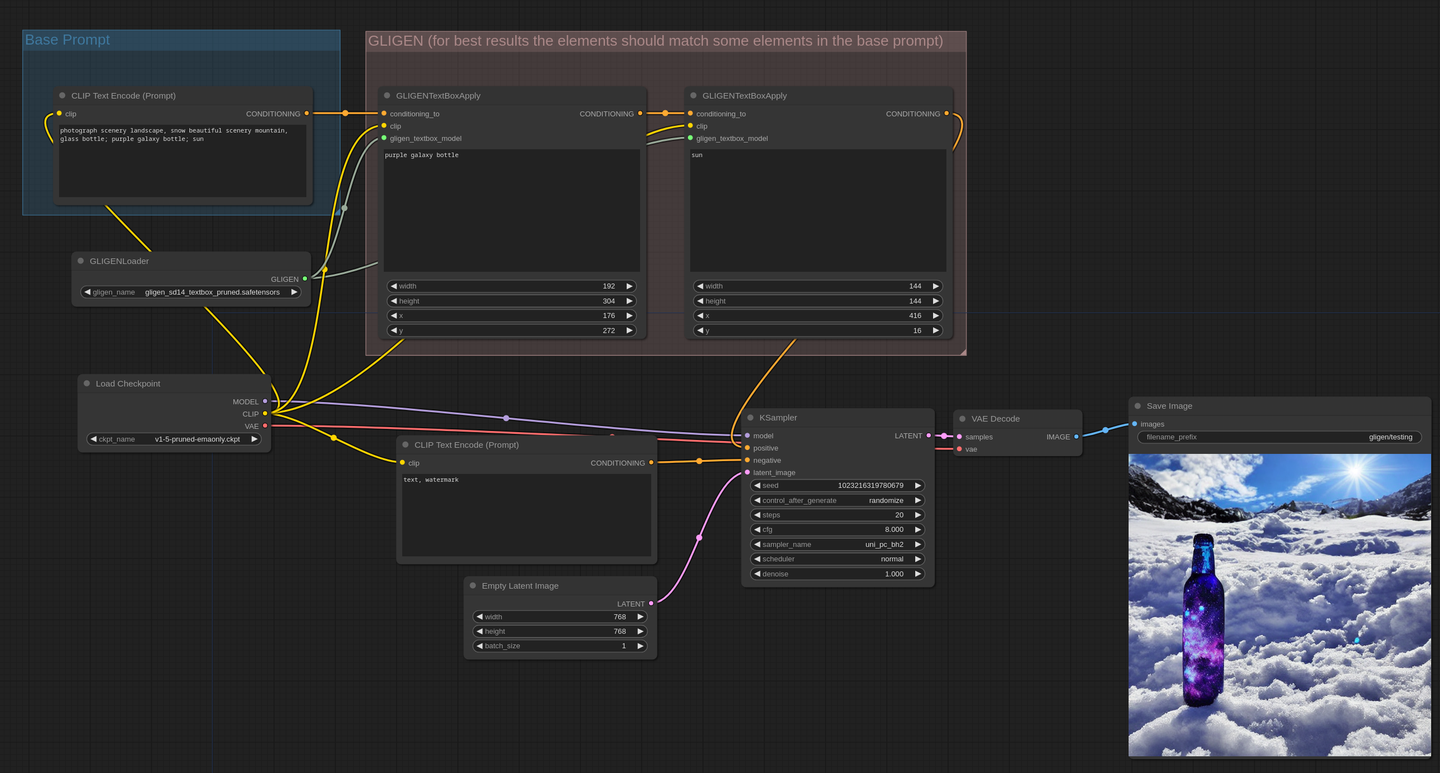
4.GLIGEN 加载器
【指定特定区域生成特定的内容】注意不适用于SXDL,请使用SD1.5模型

将 GLIGEN 模型文件放在 ComfyUI/models/gligen 目录中。
下载链接:
文本框 GLIGEN 模型允许您指定图像中多个对象的位置和大小。要正确使用它,您应该正常编写提示,然后使用 GLIGEN 文本框应用节点指定提示中某些对象/概念在图像中的位置。
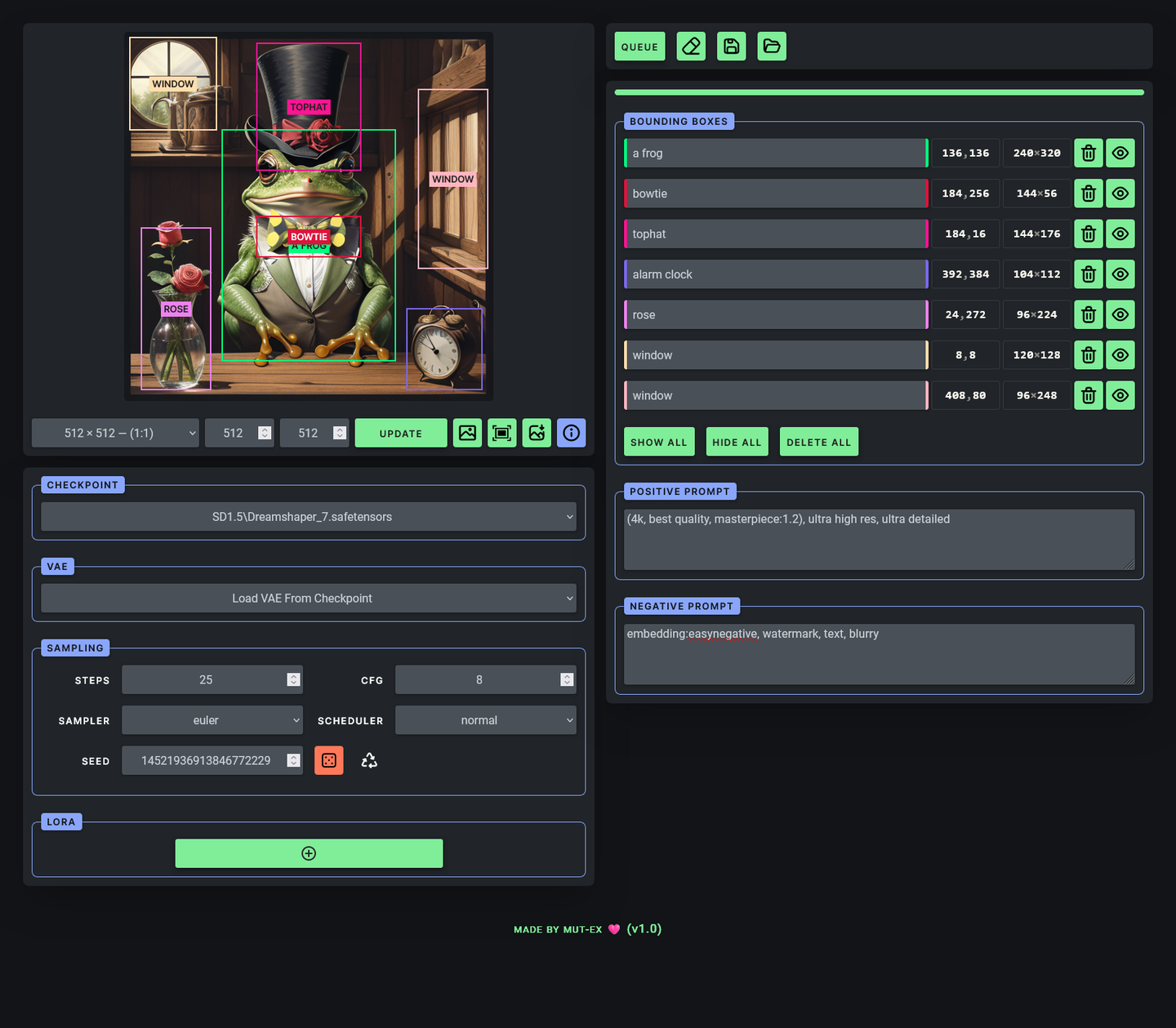
本地部署版也有了,可视化操控,更加方便。只能期待comfyUI版的插件能尽快出可视华化操作吧。
5.放大模型加载器
【图片放大时加载模型】

常见的放大算法有下面几个:
- 无/None:单纯的放大,不做任何优化处理。
- Lanczos:使用加权平均插值方法,利用原始图像自身的像素信息,增加图像的细节,从而提高图像的分辨率。传统的纯数学算法,效果一般。
- Nearest:使用简单的插值方法,基于最近邻像素的值进行插值,从而增加图像的细节和提高分辨率。传统的纯数学算法,效果一般,还不如 Lanczos 的效果好。
- LDSR:基于深度学习,通过使用轻量级的网络结构和残差学习,实现较高的超分性能和计算效率。适用于各种需要快速且准确地提高图像分辨率的应用场景,如实时视频处理、移动设备图像处理等。
- ESRGAN:全称Enhanced Super-Resolution Generative Adversarial Networks (增强超分生成对抗网络),基于深度学习的超分辨率算法。增加了很多看上去很真实的纹理,但是有时可能会过度拟合,出现不好的效果。
- 4x-UltraSharp:基于ESRGAN做了优化,比较适合处理真人。
- ESRGAN_4x:Real ESRGAN,完全使用纯合成数据来尽量贴近真实数据进行训练。腾讯贡献。
- R-ESRGAN 4x+:基于Real ESRGAN的优化模型,适合放大真实风格的图片,常用。
- R-ESRGAN 4x+ Anime6B:基于Real ESRGAN的优化模型,适合放大动漫风格的图片,常用。这个模型是专供动画使用的, 用在真人视频会有很重的涂抹感
- ScuNET GAN:基于深度学习,使用生成对抗网络(GAN)进行训练。主要用在提高图像的视觉效果和感知质量,例如在图像增强、视频处理等。
- ScuNET PSNR:基于深度学习,使用均方误差(PSNR)进行训练。主要用在提高图像的客观质量和准确性,例如在医学图像分析、监控视频处理等。
- SwinIR_4x:使用Swin Transformer思想,基于自注意力机制的Transformer结构,适合各种图像的超分,比较通用。

04) 【Upscaler2】 用来避免 Upscaler1 过度处理的问题,比如磨皮太严重。可以使用一些普通方法算法,比如 Lanczos。Upscaler2 【可见度】是指图片放大时使用 Upscaler2 算法进行处理的比例,为0时完全不使用 Upscaler2,为1时只使用 Upscaler2。
算法模型下载:
放到文件夹modelsupscale_models3)算法组合建议
放大算法1 与 放大算法2 的设置建议
想出图锐度优先:
- 放大算法1选择「4x-UltraSharp」、「R-ESGAN 4x+」
- 放大算法2选择「Lanczos」作为细节补充
想出图细节优先:
- 放大算法1选择「Lanczos」
- 放大算法2选择「Lanczos」作为锐度补充
4x-UltraSharp,BSRGAN,R-ESRGAN 4x+这3种算法放大效果还行,锐化有点严重,可以搭配放大算法2综和一下,效果应该会更好。
测试下来LDSR(效果认为是最好的,但非常非常耗时,慎重考虑),R-ESRGAN 4x+ Anime6B(网上建议动漫图片使用)
6.风格模型加载器
【风格迁移】
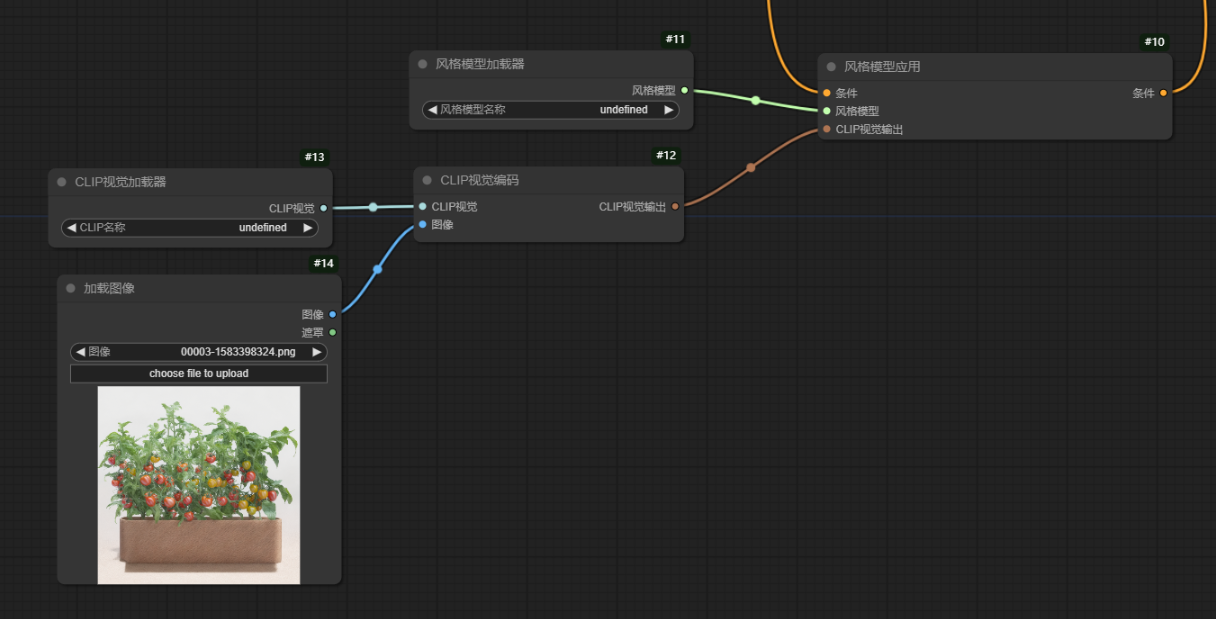
看了很多大佬的视频,发现单独去学某一个节点的方法确实不可取,大家尽量不在踩坑了。还是去工作流中去学习与使用吧。但是了解一下各节点的作用还是有必要的。
四、条件类
加在模型与K采样器中间,充当指挥官,下达命令,设定生成条件。
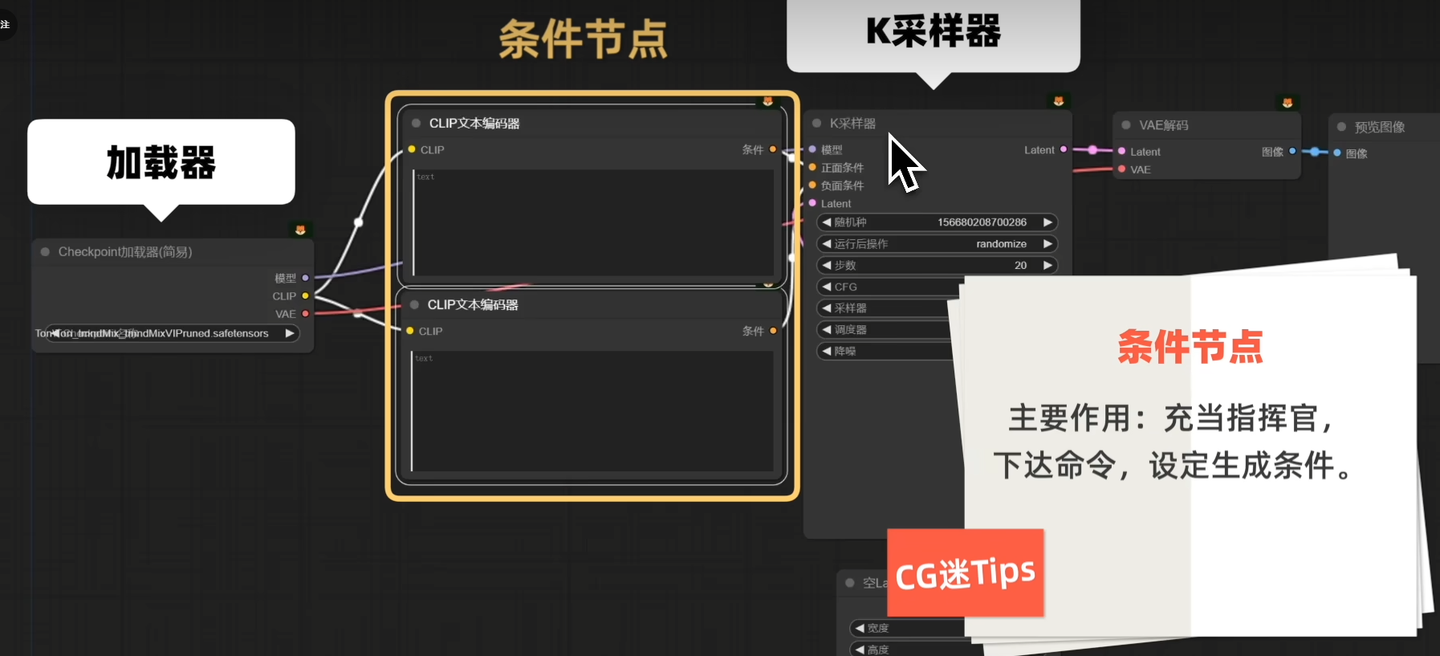
五.插件类
1.segment anything
【扣图、蒙版】

segment anything语义分割,在这里的作用就是抠图使用。看起来不是眼熟,像不像WebUI里的Inpaint anything的阉割版。
G-DinoSAM语义分割输入:SAM模型、G-Dino模型和加载图像;
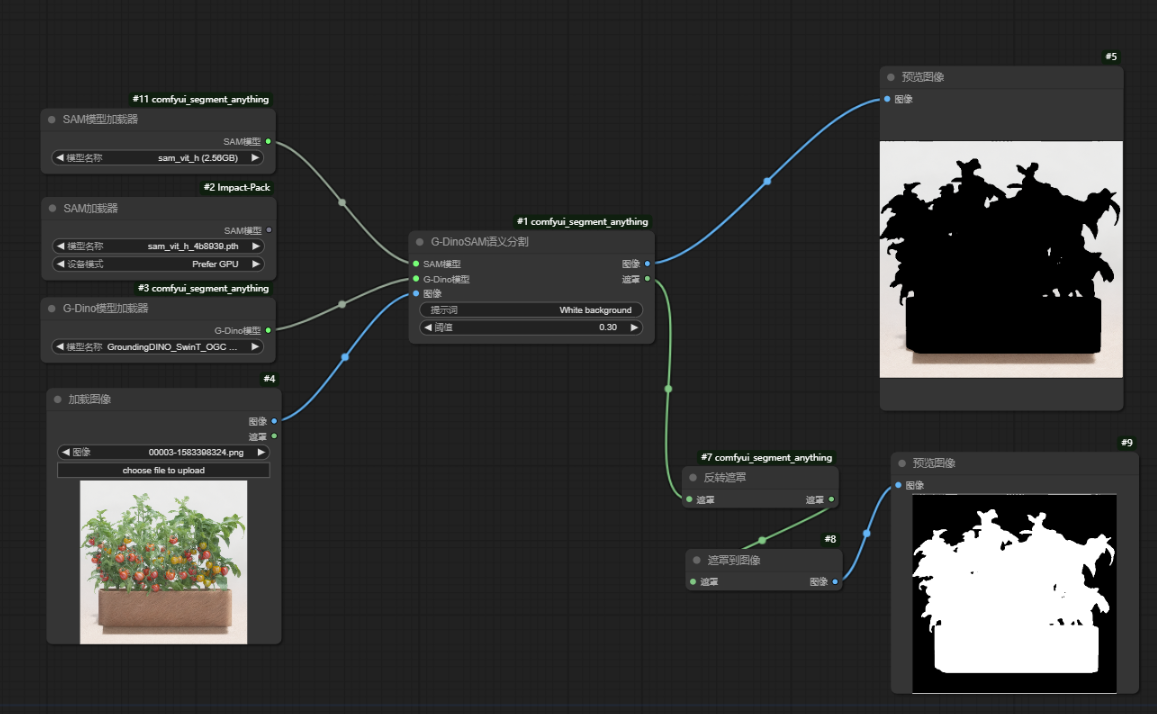
提示词 ->要选择对象的名称
阈值->提高识别的精度
输出遮罩—>给到BrushNet的遮罩节点
缺点:有些复杂的图片对象比较难用关键词去选取到对的对象,控制性不强。(人物识别没有问题)这情况我们可以选择使用PS扣图后当蒙版使用。
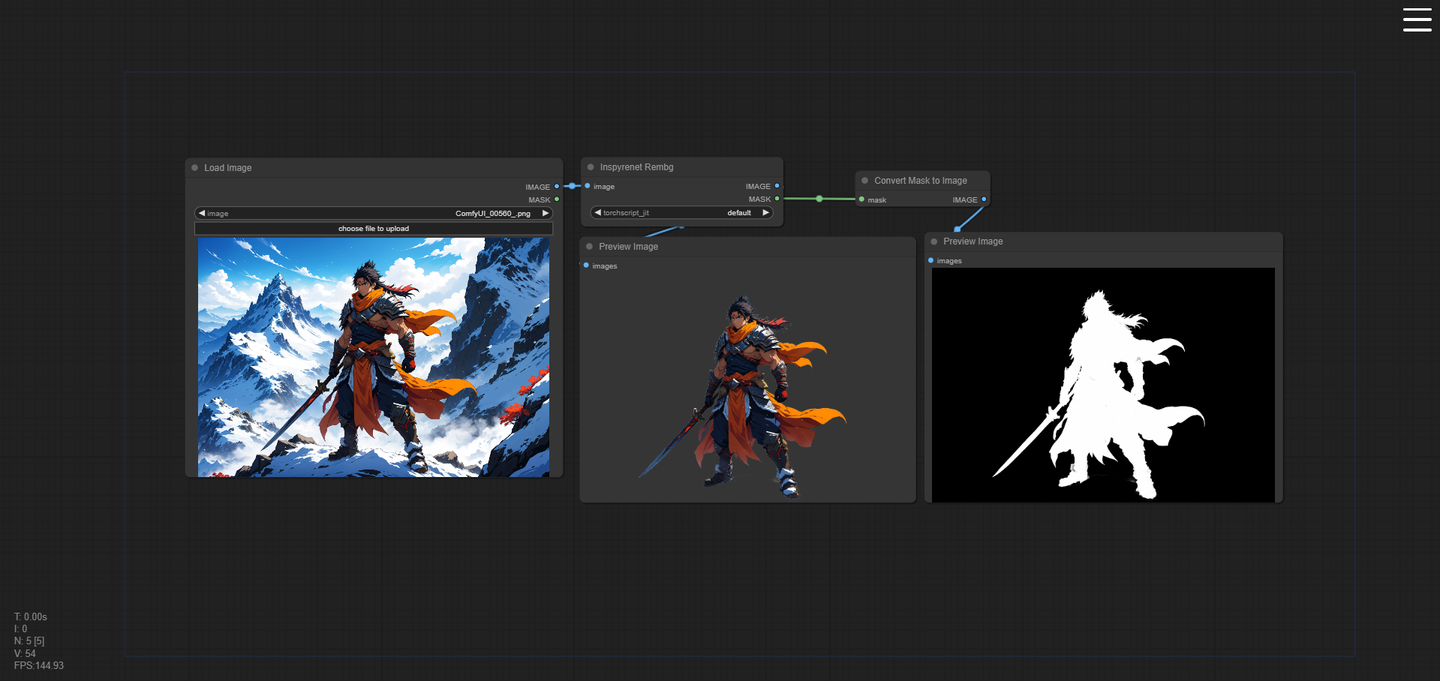
1.1.Inspyrenet-Rembg
【用于背景去除】
直接搜索并安装,与其他方法相比,rembg 质量更佳(快来尝试一下!)
可以将一批图像作为输入
针对图像批处理进行了优化,成为最快的 rembg 节点(完美适用于视频帧)
输出图像和相应的蒙版
2.BrushNet
【局部重绘】
ComfyUI BrushNet 是一种先进的图像重绘模型。使用 BrushNet 进行修复的准确率和质量远高于 ComfyUI 中的默认重绘。

3.Controlnet
安装那些不说了,大同小异,我是共享WebUI的。下载地址和各个模型的作用什么的可以参考我的另一篇专门讲controlnet的文章:

这里就讲下它的工作流,个人也是比较奇怪,玩WebUI时,经常会用controlnet,怎么感觉ComfyUI的工作流中反而用得不多呢?
4.Anything Everywhere
【省略连线】
该Anything Everywhere节点有一个输入,最初标记为“任何内容”。将任何内容连接到它(直接 – 而不是通过重新路由),输入名称将更改为与输入类型匹配。断开连接后,它将恢复为“任何内容”。
当您运行提示时,工作流中任何位置与该类型匹配的任何未连接的输入都将表现得好像连接到相同的输入一样。
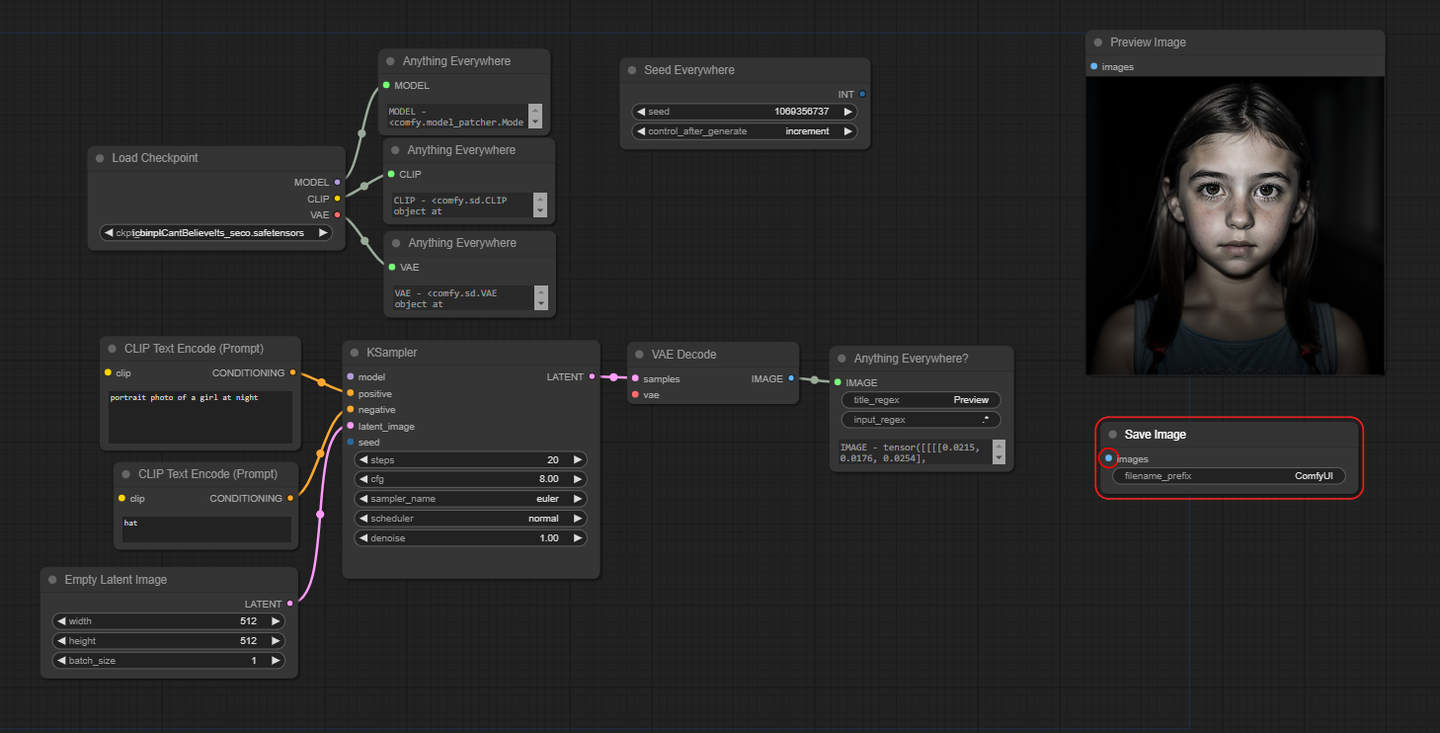
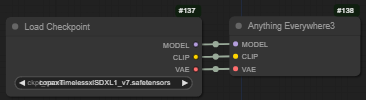
实际上只是三个Anything Everywhere节点打包在一起。专为 Checkpoint Loader 的输出而设计。
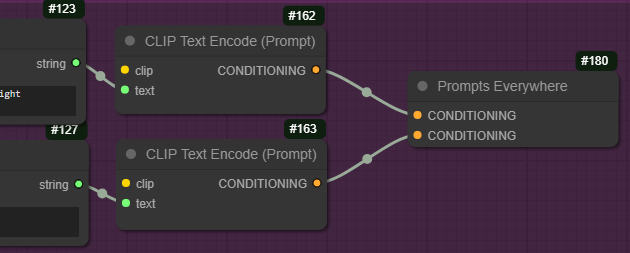
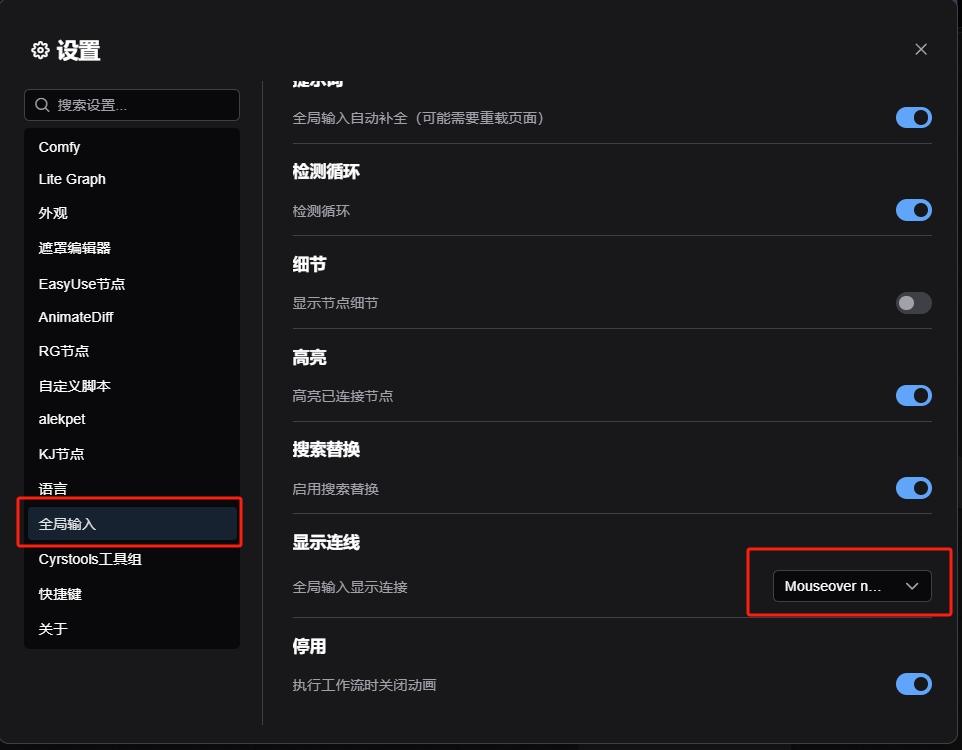
将鼠标放在 Anything Everywhere 节点上,便会显示出隐藏的连接线;如果没有显示连线,则可以在设置中更改显示连线。
![[绘画教程] Comfyui,最强图片编辑模型轻松脱衣,支持50系列显卡-AIGC VIP部落](http://aigc.vvipblog.net/wp-content/uploads/2025/07/1752548383-61cd49faf155bb2-300x188.png)



暂无评论内容