

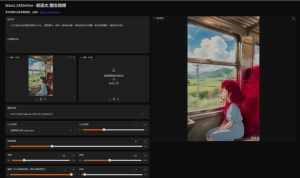
Wan2.2AllInOne V6版 – 极速AI视频生成神器,新增Lora 更新Mega V12模型,支持NSFW WebUI+ComfyUI工作流 一键整合包下载
Wan2.2 AllInOne 是阿里万相团队开源的 WAN2.2 视频模型的“大一统”整合版本,通过融合多款子模型实现极速视频生成,兼具影视级画质与简洁操作,是当前 AI 视频生成领域的标志性工具。 Wan2.2A...
AI Toolkit LoRA训练新手保姆级教程 ,附Z-image-lora详细训练教程
摘要:AI Toolkit是由Ostris开发的一站式扩散模型训练套件,专为消费级硬件设计,提供最新模型训练支持。该项目具有多模型支持、硬件兼容性强、多模态训练和灵活部署等特点。用户可通过GUI或CLI...

Z-Image – 秒级生成+照片级逼真文生图神器 8G显存可用 支持50系显卡 WebUI+ComfyUI工作流 一键整合包下载
Z-Image(造相)是阿里巴巴通义实验室最新开源的一个强大且高效的图像生成模型,凭借轻量参数实现重量级模型的视觉质量,支持中英双语渲染并在消费级显卡上实现秒级出图。 今天分享的 Z-Imag...

Wan2.2-I2V-A14B-Moe模型:MoE架构重构视频生成,消费级显卡实现电影级效果
一、Wan2.2 Moe加速模型介绍 Wan2.2-I2V-A14B-Moe-Distill-Lightx2v 是在 Wan2.2-I2V-A14B 基础上构建的高级图像到视频生成模型。这种方法允许模型生成推理步骤明显减少的视频(4 步,高噪声 2...
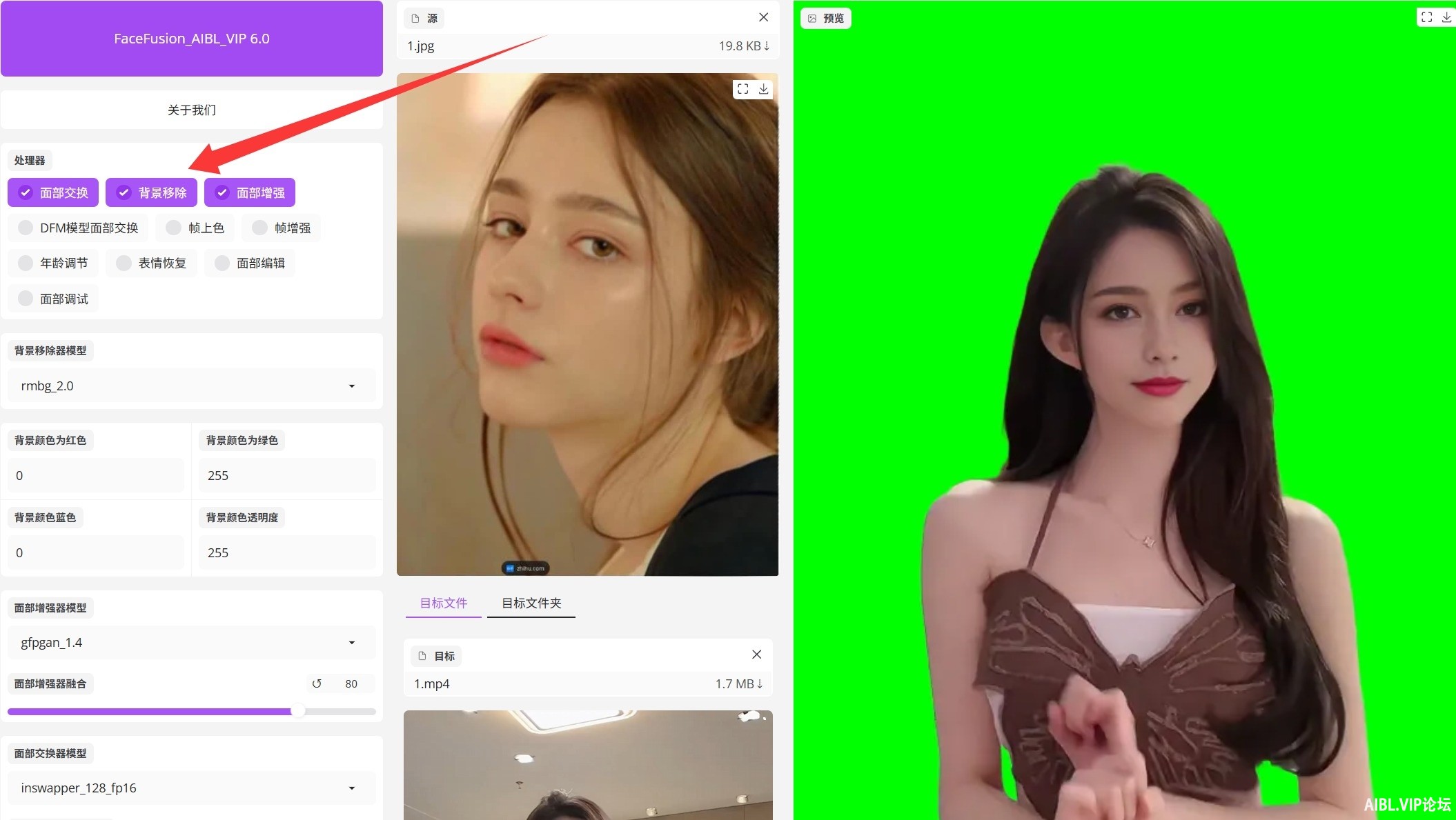
FaceFusion6.0最新版本(N卡专用兼容50系列)批量视频换脸整合包下载地址
FaceFusion换脸工具6.0最新版本换脸工具整合包, , 支持目标文件夹批量处理, 无需配置任何环境,解压即用,本地版本,无需联网也可使用,一次下载,永久免费使用 FaceFusion软件功能:图片换...
抖音上爆吹的克隆语音之王IndexTTS2,AI语音克隆神器
最近刷抖音,是不是发现有很多熟悉的香港配音的唐僧,说着很社会的话?或者在B站发现评论区突然多了一堆“AI语音整活”视频,点进去一听,好家伙,赵本山讲英语、郭德纲唱Rap、甚至特朗普用中文...

字节跳动Seedream 4.0图像创作新突破:文生图、图像编辑、组图生成
ComfyUI官方宣布字节跳动的Seedream 4.0 已集成至 ComfyUI,通过官方 API 节点即可直接调用,无需额外部署,开箱即用。(⚠️注:API从Comfyui官方调用需要付费,模型未开源) 一、字节跳动Seed...
GPT-SoVITS_V4一键整合包
GPT_SoVITS的介绍 GPT_SoVITS 是一种结合了 GPT(生成预训练模型)和 SoVITS(Singing Voice Conversion via Variational Information Bottleneck Technology)的模型,主要用于声音(主要是歌...
FaceFusion4.0最新版(N卡专用支持50系列)批量视频换脸整合包下载地址
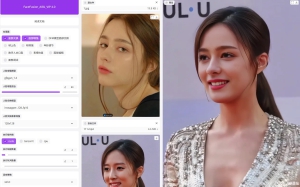
FaceFusion换脸工具4.0最新版本换脸工具整合包(2025年6月23日更新),无需配置任何环境,解压即用,本地版本,无需联网也可使用,一次下载,永久免费使用 FaceFusion软件功能:图片换脸,视频换脸...

人体艺术摄影模型——蝴蝶映像1.0
蝴蝶映像1.0 蝴蝶映像旨在做一个艺术摄影特别是人体艺术摄像的模型,在现实写真、电商摄影、电商人像摄影、艺术写真、人体艺术写真方面进行了具有针对性的训练,在写真方面特别是人体写真方面已...
