

一、Wan2.2 Moe加速模型介绍
Wan2.2-I2V-A14B-Moe-Distill-Lightx2v 是在 Wan2.2-I2V-A14B 基础上构建的高级图像到视频生成模型。这种方法允许模型生成推理步骤明显减少的视频(4 步,高噪声 2 步,低噪声 2 步),并且没有无分类器引导,从而大大缩短视频生成时间,同时保持高质量的输出。
-
Wan2.2 的训练挑战在于高噪声;因此,我们重点介绍了高噪声模型的两步训练。与之前的版本相比,我们采用了几种新的策略,提高了模型的一致性和动态性。 -
Wan2.2 的低噪声模型直接使用 Wan2.1 的 lora 可以取得良好的效果;因此,低噪声型号仍然采用旧的 Wan2.1 LoRA。
用这个模型,在保持动态效果不错的情况下,生成时间大大缩短,还是值得玩玩的。

二、相关安装(文末网盘)
蒸馏的moe大模型,有28G,本地跑记得开fp8量化模型,这样16G才可以跑起来。
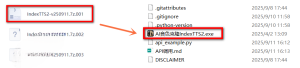
模型地址:https://huggingface.co/lightx2v/Wan2.2-I2V-A14B-Moe-Distill-Lightx2v
显卡生成时间参考:

模型路径:
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
│ ├───📂 loras/
│ │ ├─── wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
│ │ └─── wan2.2_i2v_lightx2v_4steps_lora_v1_low_noise.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors
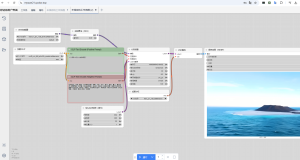
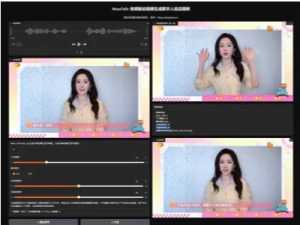
三、工作流及体验
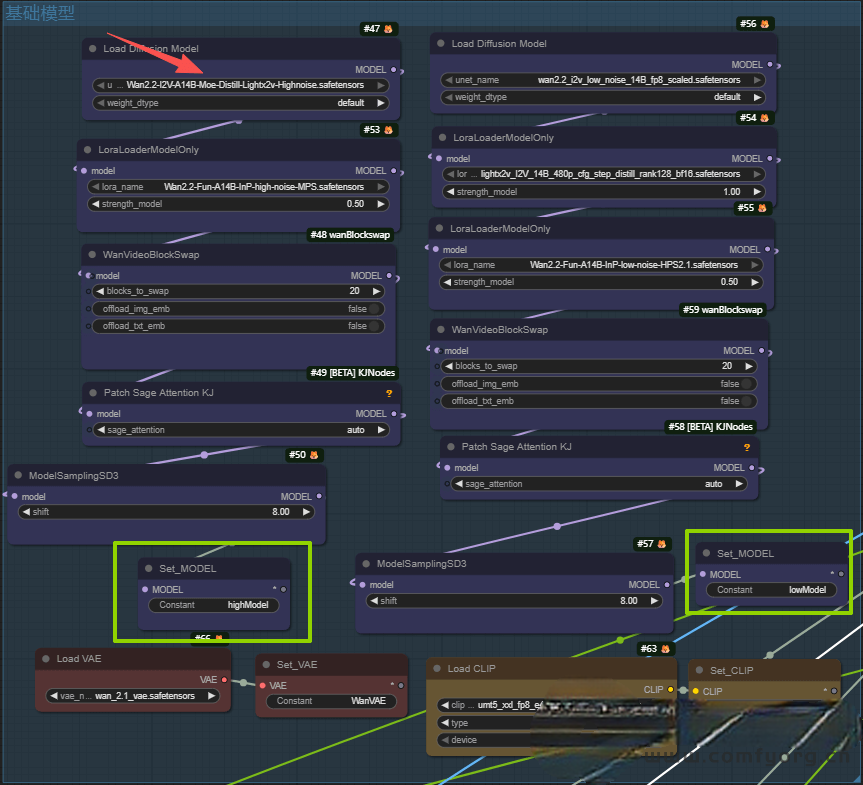
工作流官版示例:核心是高噪使用加速蒸馏大模型,低噪的还是用官版的I2V模型配合2.1的Lightx2v来跑,这是该模型官方推荐的搭配方案。
模型组成:模型+loras(高低噪这里我还分别加了奖励模型,会有更好的动态和细节。)
视频处理:
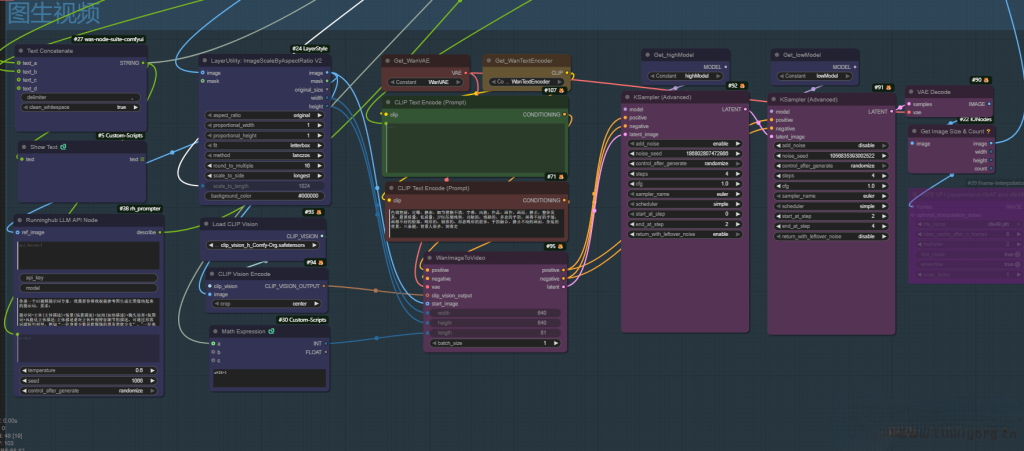
效果演示

Wan2.2代表了视频生成技术的重大飞跃,拥有创新的专家混合(MoE)架构,利用双专家设计进行去噪,提升了视频生成的质量和收敛性。这个模型不仅仅是一个渐进式的更新;它引入了高压缩视频生成能力,实现了令人印象深刻的质量。
Wan2.2的独特之处在于其性能,超越了领先的闭源商业模型,在生成模型领域取得了显著成就。对于对尖端视频生成感兴趣的开发人员和研究人员,Wan2.2可在Apache 2.0许可下获得,提供自由和合规的平衡。该模型的能力涵盖了文本到视频和图像到视频任务,使其成为各种应用的多功能工具。如果您渴望探索视频生成技术的前沿,Wan2.2绝对值得您关注。
相关模型下载(Wan2.2截至目前的所有模型)
Wan2.2-I2V-A14B-Moe-Distill-Lightx2v
![[绘画教程] Comfyui,最强图片编辑模型轻松脱衣,支持50系列显卡-AIGC VIP部落](http://aigc.vvipblog.net/wp-content/uploads/2025/07/1752548383-61cd49faf155bb2-300x188.png)


暂无评论内容