
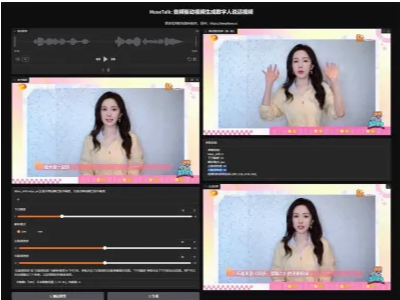
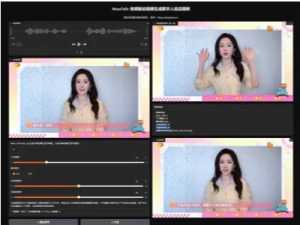
 MuseTalk 是腾讯开发的一款AI数字人唇形同步工具,它能根据输入的音频自动调整虚拟人物的嘴部动作,让数字人说话时的口型和声音完美匹配。只需要上传一段驱动音频,和一段人物视频,即可一键生成无限说自认说话视频,适用各种自媒体口播和直播等领域! MuseTalk 对于最低硬件要求,在 Windows 环境下使用配备 4GB 显存的 NVIDIA GeForce RTX 3050 Ti 笔记本 GPU 测试了该系统。在 fp16 模式下,生成 8 秒的视频大约需要 5 分钟。今天分享的MuseTalk V3版,同步官方最新的 MuseTalk V1.5版模型。与 1.0 版本相比,这个版本的模型有了显著改进,提高了清晰度、身份一致性和精确的唇音同步。 应用领域:
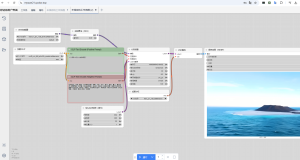
上传驱动音频和参考视频,设置相关参数(对应参数都有详细说明),生成即可。 批量生成使用说明:
一个视频对应一个task,以此类推,把所有的素材放到一个目录里,比如存放在data下的video和audio,一个存放视频,一个存放音频,注意视频和音频文件名不要搞错了。 下载地址: [rihide]123云盘:https://www.123684.com/s/OYeA-ed1Bh 提取码:6666 备用链接:https://www.123912.com/s/OYeA-ed1Bh 提取码:6666[/rihide] |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
![[绘画教程] Comfyui,最强图片编辑模型轻松脱衣,支持50系列显卡-AIGC VIP部落](http://aigc.vvipblog.net/wp-content/uploads/2025/07/1752548383-61cd49faf155bb2-300x188.png)




暂无评论内容